<머신러닝. 딥러닝 문제해결 전략> 2부 6장 실습하고 해당 내용을 정리한 내용입니다.
1. 경진대회 이해
https://www.kaggle.com/competitions/bike-sharing-demand
Bike Sharing Demand | Kaggle
www.kaggle.com
2부 6장에서 사용되는 경진대회는 자전거 대여 수요 예측 경진대회 입니다.
2014년 5월에서 2015년 5월까지 약 1년 동안 개최되었던 대회이며, 총 3,242팀이 참가했습니다.

대회의 주된 내용은 워싱턴 D.C의 자전거 무인 대여 시스템 과거 기록을 기반으로 향후 자전거 대여 수요를 예측하는 대회입니다. 또한 본 대회는 플레이그라운드 대회로 난이도가 낮은 연습용 대회입니다. 따라 처음 입문자가 프로세스를 익히고 실력을 키우기에 적합한 대회로 볼 수 있습니다.
데이터에 관해 대략적인 파악과 제출해야하는 평가 지표를 먼저 살펴보도록 하겠습니다.

주어진 데이터는 2011년부터 2012년까지 2년간의 자전거 대여 데이터입니다.
해당 대여 데이터는 한 시간 간격으로 기록되어 있으며, 그 중 훈련 데이터는 매달 1일부터 19일까지, 테스트 데이터는 매달 20일부터 월말까지의 기록입니다.
또한 피처는 대여 날짜, 시간, 요일, 계절, 날씨, 실제 온도, 체감 온도, 습도, 풍속, 회원 여부 입니다.
해당 피처에 대한 상세 내용은 아래의 표와 같습니다.
| 피처명 | 설명 |
| datetime | 기록 일시 (1시간 간격) |
| season | 계절 (1: 봄, 2: 여름, 3: 가을, 4: 겨울) |
| holiday | 공휴일 여부 (0: 공휴일 아님, 1: 공휴일) |
| workingday | 근무일 여부 (0: 근무일 아님, 1: 근무일) * 주말과 공휴일이 아니면 근무일이라고 간주 |
| weather | 날씨 (1: 맑음, 2: 옅은 안개, 약간 흐림, 3: 약간의 눈, 약간의 비와 천둥 번개, 흐림, 4: 폭우와 천둥 번개, 눈과 짙은 안개) * 숫자가 클수록 날씨가 안 좋음 |
| temp | 실제 온도 |
| atemp | 체감 온도 |
| humidity | 상대 습도 |
| windspeed | 풍속 |
| casual | 등록되지 않은 사용자(비회원) 수 |
| registered | 등록된 사용자(회원) 수 |
| count | 자전거 대여 수량 |

해당 대회의 평가지표는 RMSLE 이며, 제출 형태는 일시(datetime)와 대여 수량(count)로 구성되어 있는 것을 알 수 있습니다.
2. 탐색적 데이터 분석
해당 대회에 대해 대략적으로 파악했으니 다음은 코드를 통해 데이터를 파악해보도록 하겠습니다.
책의 저자분께서 참고하신 원본 코드는 다음과 같습니다.
https://www.kaggle.com/code/viveksrinivasan/eda-ensemble-model-top-10-percentile
EDA & Ensemble Model (Top 10 Percentile)
Explore and run machine learning code with Kaggle Notebooks | Using data from Bike Sharing Demand
www.kaggle.com
01. 캐글 노트북 환경설정
캐글 노트북 환경이 기본적으로 제공하는 라이브러리들은 시간이 흐름에 따라 조금씩 버전이 달라집니다. 최신 버전을 쓰면 좋겠지만, 버전이 다르면 실행 결과가 달라질 수 있습니다.

따라 라이브러리 버전을 책과 동일하게 일치시켜 진행하도록 하겠습니다. 이는 라이브러리 버전이 고정된 노트북 양식을 복사해서 사용하는 것으로, 공유된 노트북의 오른쪽 위 [Copy & Edit] 버튼을 클릭하면 됩니다.
위 사진의 링크 주소 입니다.
https://www.kaggle.com/code/werooring/ch6-notebook
[ch6] Notebook
Explore and run machine learning code with Kaggle Notebooks | Using data from Bike Sharing Demand
www.kaggle.com
02. 데이터 둘러보기
주어진 데이터가 어떻게 구성되어 있는지 살펴보도록 하겠습니다. 이를 위해 판다스로 훈련, 테스트, 제출 샘플 데이터를 DataFrame의 형태로 불러오겠습니다.

이후 shape() 함수로 훈련 데이터와 테스트 데이터의 크기를 확인하겠습니다.

이를 통해 훈련 데이터는 10,886행 12열로 구성되어 있고, 테스트 데이터는 6,493행 9열로 구성되어 있단 점을 알 수 있습니다. 열은 피처의 개수를 의미합니다. 하지만 현재 훈련 데이터와 테스트 데이터가 서로 다른 열을 갖고 있단 점을 파악할 수 있습니다. 따라 어떤 점이 차이가 나는지 head() 함수를 통해 파악하도록 하겠습니다.

훈련 데이터와 테스트 데이터를 head() 함수를 통해 살펴봤을 때, 테스트 데이터에서 예측해야하는 count 를 제외한 casual, registered 피처가 없는 것을 확인 할 수 있습니다. 따라 모델을 훈련할 때, 훈련 데이터의 casual과 register 피처를 제거해야 합니다.
| 분석 결과 |
| 1. casual, registered 피처 제거 |
다음으로 제출 샘플 파일이 어떻게 생겼는지 살펴보겠습니다.

제출 파일은 보통 이런 형태로 데이터를 구분하는 ID(여기서는 datetime) 값과 타깃값으로 구성되어 있습니다. 현재는 타깃값인 count가 모두 0입니다. 시간대별 대여 수량을 예측해 이 값을 바꾼 뒤 제출하면 됩니다. 여기서 ID 값인 datetime은 데이터를 구분하는 역할만 하므로 타깃값을 예측하는 데에는 도움을 주지 않습니다. 따라 추후 모델 훈련시 데이터에 있는 datetime 피처는 제거할 예정입니다.
| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
info() 함수를 사용하면 DataFrame 각 열의 결측치가 몇 개 인지, 데이터 타입은 무엇인지 파악할 수 있습니다.
먼저 훈련 데이터부터 살펴보겠습니다.

모든 피처의 비결측값 데이터 개수(Non-Null Count)가 전체 데이터 개수와 똑같은 10,866개이므로 훈련 데이터에는 결측값이 없습니다. 만약 결측값이 있다면 적절히 처리하는 과정이 필요합니다.
데이터 타입은 object, int64, float64로 다양합니다.
테스트 데이터도 살펴보겠습니다.

테스트 데이터에도 결측값이 없고, 데이터 타입도 훈련 데이터와 동일합니다.
이상으로 사용할 데이터의 모습을 간단히 둘러보았습니다.
03. 더 효과적인 분석을 위한 피처 엔지니어링
기본적인 분석을 마쳤다면 다음은 데이터 시각화 차례입니다. 데이터를 다양한 관점에서 시각화 해보면 날 데이터(raw data) 상태에서는 찾기 어려운 경향, 공통점, 차이 등이 드러날 수 있기 때문입니다. 하지만 일부 데이터는 시각화하기에 적합하지 않은 형태일 수도 있습니다. 해당 대회에서는 datetime 피처가 해당됩니다. 따라 시각화하기 전에 이 피처를 분석하기 적합하게 변환 (피처 엔지니어링) 해주는 과정이 필요합니다.
datetime 피처의 데이터 타입은 object입니다. 판다스에서 object 타입은 문자열 타입에 해당합니다. datetime은 연도, 월, 일, 시간, 분, 초로 구성되어 있습니다. 따라서 세부적으로 분석해보기 위해 구성요소별로 나누어보겠습니다. 이때 파이썬 내장 함수인 split()함수를 이용하며, datetime의 100번째 원소를 기준으로 설명하겠습니다.

| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
| 3. 연도, 시간, 월, 일, 시간, 분, 초 피처 추가 |
datetime 피처는 object 타입이기 때문에 문자열처럼 다룰 수 있습니다. 앞의 예에서는 split()함수를 사용해 공백 기준으로 앞 뒤 문자를 나누었습니다. 이때 앞의 문자열인 '2011-01-05'는 날짜 문자열이고, 두 번째 문자열 '09:00:00'은 시간 문자열입니다.
날짜 문자열은 "-" 문자를 기준으로 연도, 월, 일로 나누고, 시간 문자열은 ":"을 기준으로 시, 분, 초로 나누겠습니다.

다음과 같이 나눠지는 것을 확인 할 수 있습니다. 이를 적용하여 판다스 apply() 함수를 통해 datetime에 적용해 날짜(date), 연도(year), 월(month), 일(day), 시(hour), 분(minute), 시(second) 피처를 생성하겠습니다.

apply() 함수는 DataFrame의 데이터를 일괄 가공해주는 역할을 합니다. 이는 위와 처럼 종종 람다 함수와 함께 사용됩니다. 즉, 람다 함수를 DataFrame 축(기본값은 DataFrame의 각 열에 대해 수행)을 따라 적용하는 기능을 한다고 할 수 있습니다.
이제 요일 피처도 생성해보겠습니다. 요일 피처는 calender와 datetime '라이브러리'를 활용해 만들 수 있습니다. 여기서 datetime은 날짜와 시간을 조작하는 라이브러리로 datetime 피처와는 다른 것입니다. 날짜 문자열에서 요일을 추출하는 방법을 한 단계씩 알아보겠습니다.

calendar와 datetime 라이브러리를 사용하면 요일 피처를 문자로 구할 수 있습니다. 이때, 0은 월요일, 1은 화요일, 2는 수요일 순으로 매핑됩니다. 단, 머신러닝 모델은 숫자만 인식하므로 모델을 훈련할 때는 피처 값은 문자로 바꾸면 안된다는 점을 주의해야 합니다. 문자 피처 역시 모두 숫자로 변환해주는 작업이 필요합니다. 여기서는 그래프로 나타냈을 때 쉽게 알아보려고 요일 피처를 문자열로 바꾼 것입니다.
| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
| 3. 연도, 시간, 월, 일, 시간, 분, 초 피처 추가 |
| 4. 요일 피처 추가 |
앞의 로직을 apply() 함수를 적용해 요일(weekday) 피처를 추가하겠습니다.

다음은 season과 weather 피처의 차례입니다. 이 두 피처는 범주형 데이터인데 현재 1, 2, 3,4라는 숫자로 표현되어 있습니다. 이러한 숫자로는 시각화 시 의미를 파악하기 어렵습니다. 따라 의미가 잘 드러나도록 map() 함수를 사용하여 문자열로 바꾸겠습니다.

이제 훈련 데이터의 첫 5행을 출력해 피처가 어떻게 바뀌었는지 보겠습니다.

1. date, year, month, day, hour, minute, second, weekday 피처가 추가 되었고,
2. season과 weather 피처는 숫자에서 문자로 바뀌었습니다.
하지만 date 피처가 제공하는 정보는 모두 year, month, day 피처와 중복되므로 추후 이를 제거해주는 과정이 필요해보입니다. 또한 세 달씩 month를 묶으면 season과 동일한 의미의 피처가 됩니다. 지나치게 세분화된 피처를 더 큰 분류로 묶으면 성능이 좋아지는 경우가 있어 여기서는 season 피처만 남기고 month 피처는 제거 하도록 하겠습니다.
| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
| 3. 연도, 시간, 월, 일, 시간, 분, 초 피처 추가 |
| 4. 요일 피처 추가 |
| 5. date 피처 제거 |
| 6. month 피처 제거 |
04. 데이터 시각화
피처를 추가한 데이터를 그래프로 시각화 해보겠습니다. 시각화는 데이터 분포나 데이터 관계를 한 눈에 파악할 수 있으며 또한 모델링에 도움될 만한 정보를 얻을 수도 있습니다. 따라 탐색적 데이터 분석에서 가장 중요한 부분입니다.
시각화를 위해 matplotlib과 seaborn 라이브러리를 활용하겠습니다. 이때 matplotlib은 파이썬으로 데이터를 시각화할 때 표준처럼 사용되는 라이브러리이며, seaborn은 matplotlib에 고수준 인터페이스를 덧씌운 라이브러리입니다.
먼저 두 라이브러리를 임포트합니다.

이때 추가로 %matplotlib inline 을 추가하면 matplotlib이 그린 그래프를 주피터 노트북에서 바로 출력해줍니다. 하지만 캐글 환경에서는 %matplotlib inline이 없어도 그래프를 보여줍니다. 그럼에도 matplotlib을 사용하는 경우 관습적으로 쓰는 경향이 있어서 추가하겠습니다.
- 분포도
분포도는 수치형 데이터의 집계 값을 나타내는 그래프 입니다. 집계 값은 총 개수나 비율 등을 의미합니다. 따라 타깃값인 count의 분포도를 그려보겠습니다. 왜냐하면 타깃값을 분포를 알면 훈련 시 타깃값을 그대로 사용할지 변환해 사용할지 파악할 수 있기 때문입니다.

그래프에서 x축은 타깃값인 count를 의마하고, y축은 총 개수를 나타냅니다. 분포도를 살펴보면 타깃값인 count가 0 근처로 분포가 왼쪽으로 많이 편향되어 있다는 것을 알 수 있습니다. 회귀 모델이 좋은 성능을 내기 위해서는 데이터가 정규분포를 따라야 하는데, 현재 타깃값 count는 정규분포를 따르고 있지 않습니다. 따라 현재 타깃값을 그대로 사용해 모델링한다면 좋은 성능을 기대하기 어렵습니다.
이럴때 데이터 분포를 정규분포에 가깝게 만들기 위해 가장 많이 사용되는 방법은 로그변환입니다. 로그변환은 count 분포와 같이 데이터가 왼쪽으로 편향되어 있을 때 사용합니다. 로그변환하는 방법은 원하는 값에 로그를 취해주면 됩니다. 따라 count를 로그변환해서 로그변환한 값의 분포를 살펴보도록하겠습니다.

변환 전보다 정규분포에 가까워진 것을 확인할 수 있습니다. 앞서 타깃값 분포가 정규분포에 가까울수록 회귀 모델 성능이 좋다고 했습니다. 따라 피처를 바로 활용해 count를 예측하는 것보다 log(count)를 예측하는 편이 더 좋은 성능을 기대할 수 있단 것을 알 수 있습니다. 따라 예측시에 타깃값을 log(count)로 변환해서 사용하겠습니다.
하지만 마지막에는 지수변환을 하여 실제 타깃값인 count로 복원해야합니다. 다음 수식이 나타내는 바와 같이 log(y)를 지수변환하면 y가 된다는 것을 알 수 있습니다.

위의 내용을 표로 정리하면 다음과 같습니다.
| 구분 | 기본 타깃값 활용 시 | 로그변환한 타깃값 활용 시 |
| 타깃값 | y | log(y) |
| 타깃값 분포 | y값 분포 (비대칭 분포) |
로그변환 후 y값 분포 (정규분포) |
| 회귀 모델 예측 성능 | 나쁨 | 좋음 |
| 후처리 | 필요없음 | log(y)에서 실제 타깃값인 y를 복원하기 위해 지수변환을 해줘야 함 |
| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
| 3. 연도, 시간, 월, 일, 시간, 분, 초 피처 추가 |
| 4. 요일 피처 추가 |
| 5. date 피처 제거 |
| 6. month 피처 제거 |
| 7. 타깃값을 count가 아닌 log(count)로 변환해 사용 |
| 8. 마지막에는 지수변환하여 count로 복원 |
- 막대 그래프
다음으로 연도, 월, 일, 시, 분, 초별로 총 여섯 가지의 평균 대여 수량을 막대 그래프로 그려보겠습니다. 이 피처들은 범주형 데이터입니다. 각 범주형 데이터에 까라 평균 대여 수량이 어떻게 다른지 파악하려고 합니다. 그래야 어떤 피처가 중요한지 알 수 있습니다. 이럴 때 막대 그래프를 이용합니다. 막대 그래프는 seaborn의 barplot() 함수로 그릴 수 있습니다.
총 3개 스탭으로 나눠서 그래프를 그린 후, 이를 파악해보도록 하겠습니다. 편의상 코드를 나눠 설명하지만, 스텝 1~3 코드는 한 셀에서 실행해야 정상적으로 동작 합니다.
스텝 1: m행 n열 Figure 준비하기
첫 번쨰로 총 6개의 그래프(서브플롯)를 품는 3행 2열짜리 Figure를 준비합니다.

코드 (1)은 matplotlib 라이브러리의 subplots() 함수 사용 예시입니다. 이는 여러 그래프를 동시에 그릴 때 사용합니다. 파라미터를 2개 받는데 nrow는 행 개수를, ncols는 열 개수를 뜻합니다. 따라 (1)을 실행하면 3행 2열의 서브플롯 전체가 figure 변수에 할당되며, 각각의 서브플롯 축 6개는 axes 변수에 할당됩니다. 다음 그림은 (1)까지만 실행해 figure을 출력한 결과 입니다.

이어서 axes에는 어떤 객체가 할당되어 있는지 출력해보겠습니다.

AxesSubplot 객체가 6개가 3행 2열로 구성된 배열이 출력된 것을 확인할 수 있습니다. 이 배열을 입력으로 axes.shape를 실행하면 (3, 2)가 출력됩니다. 출력 결과의 각 AxesSubplot 객체는 순서대로 서브폴롯의 0행 0열 ~ 2행 1열 축을 의미합니다.
코드 (2)의 plt.tight_layout()은 서브 플롯 사이에 여백을 줘 간격을 넓히는 기능을 합니다. 이 함수를 적용한 결과를 보도록 하겠습니다.

보다시피 서브플롯 공간이 넉넉해서 기존보다 보기 좋아진 것을 알 수 있습니다.
마지막으로 코드(3)의 figure.set_size_inches(10, 9)로는 Figure 크기를 지정합니다.이는 서브플롯 하나의 크기가 아니라 서브플롯 6개를 합친 '전체' Figure 크기이며, 단위는 함수 이름에서 알 수 있듯이 인치에 해당합니다. 첫 번째 파라미터로는 너비, 두 번쨰 파라미터로는 높이를 조정합니다. 즉 여기서는 너비 10인치, 높이 9인치로 설정되었단 점을 알 수 있습니다.
스텝 2: 각 축에 서브플롯 할당
이어서 연도, 월, 일, 시간, 분 초별 평균 대여 수량 막대 그래프를 스텝 1에서 준비한 Figure의 각 축에 할당하겠습니다.

막대 그래프 생성에는 seaborn의 barplot()함수를 이용했습니다. x 파라미터에는 연도, 월, 일, 시, 분, 초를 전달하고, y 파라미터에는 대여 수량을 전달했습니다. data 파라미터에는 훈련데이터를 DataFrame 형식으로 전달했습니다. ax 파라미터에는 AxesSubplot 객체를 전달했으며, 0행 0열의 축부터 2행 1열의 축까지 순서대로 전달했습니다.
그럼 서브플롯들이 잘 설정되었는지 스텝 2코드 까지 실행해보겠습니다.

의도한대로 잘 할당되었습니다. 하지만 각 서브플롯이 어떤 정보를 표현하는지가 한눈에 잘 안들어오고, 어떤 서브폴롯은 x축 라벨이 서로 겹치는 등 아쉬운 점이 조금 보입니다.
스텝 3: (선택) 세부 설정
위의 그래프에서 아쉬움이 남는다면 다양한 형태로 세부 속성을 추가로 설정할 수 있습니다. 이번에는 각 서브플롯에 제목을 추가하고, x축 라벨이 겹치지 않게 개선해보겠습니다. 먼저 각 축에 그려진 서브플롯에 제목을 달아주겠습니다.

이에 대한 결과는 아래와 같습니다.

제목이 정상적으로 생성된 것을 확인할 수 있습니다. 이에 이어서 1행의 두 서브플롯(day, hour) x축 라벨들을 90도 회전시키겠습니다.

보다시피 axis 파라미터에 원하는 축을 명시하고 labelrotation 파라미터에 회전 각도를 입력하면 됩니다. axis의 값으로는 'x', 'y', 'both'를 지정할 수 있으며, 기본값이 'both'이므로 생략하게되면 두 축을 한꺼번에 회전시킵니다.
이상으로 세부 설정까지 모두 마쳤습니다. 이제 전체 코드와 완성된 막대그래프를 보도록하겠습니다.


이제 완성된 막대 그래프를 토대로 해당 그래프가 어떤 정보를 담고 있는지 파악해보도록하겠습니다.
먼저, 'Rental amounts by year' (연도별 평균 대여 수량) 그래프를 보겠습니다. 2011년보다 2012년에 대여가 더 많았습니다.
다음, 'Rental amounts by month' (월별 평균 대여 수량) 그래프로는 '월별 평균 대여 수량의 추세'를 파악할 수 있습니다. 평균 대여 수량은 6월에 가장 많고 1월에 가장 적습니다. 이로 날씨가 따뜻할수록 대여 수량이 많다고 짐작할 수 있습니다.
세번째, 'Rental amounts by day' (일별 평균 대여 수량) 그래프 입니다. 일별 대여 수량에는 뚜렷한 차이가 보이지 않스빈다. 소개 페이지에서 말했다시피 훈련 데이터에는 매월 1일부터 19일까지의 데이터만 있습니다. 나머지 20일부터 월말까지의 데이터는 테스트 데이터에 있습니다. 따라 일자(day)는 피처로 사용하지 못합니다. 왜냐하면 day를 피처로 사용하려면 훈련 데이터와 테스트 데이터에 공통된 값이 있어야 하는데, 훈련 데이터의 day와 테스트 데이터의 day는 전혀 다른 값을 갖고 있기 때문입니다.
네번째, 'Rental amounts by hour' (시간별 평균 대여 수량) 그래프 입니다. 그래프 모양이 쌍봉형 입니다. 새벽 4시에 대여량이 가장 적고, 아침 8시와 저녁 5~6시에 대여가 가장 많습니다. 이를 통해 당연히 새벽4시에 자전거를 타는 사람은 거의 없다는 점과 사람들이 등하교 혹은 출퇴근 길에 자전거를 많이 이용한다고 짐작해볼 수 있습니다.
다섯번째, 여섯번째에 있는 분별, 초별 평균 대여 수량 그래프는 아무 정보도 담고 있지 않습니다. 훈련데이터에 분과 초는 모두 0으로 기록되어 있기 때문입니다. 따라서 나중에 모델을 훈련할 때 분과 초 피처는 사용하지 않겠습니다.
| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
| 3. 연도, 시간, 월, 일, 시간, 분, 초 피처 추가 |
| 4. 요일 피처 추가 |
| 5. date 피처 제거 |
| 6. month 피처 제거 |
| 7. 타깃값을 count가 아닌 log(count)로 변환해 사용 |
| 8. 마지막에는 지수변환하여 count로 복원 |
| 9. day 피처 제거 |
| 10. minute, second 피처 제거 |
- 박스플롯
박스플롯은 범주형 데이텅 따른 수치형 데이터 정보를 나타내는 그래프입니다. 막대 그래프 보다 더 많은 정보를 제공하는 특징이 있습니다.
여기서는 계절, 날씨, 공휴일, 근무일 (범주형 데이터) 별 대여 수량 (수치형 데이터)을 박스플롯으로 그려보겠습니다. 각 범주형 데이터에 따라 타깃값인 대여 수량이 어떻게 변하는지 알 수 있습니다.
이번에는 2행 2열 Figure로 만들 것이며, 코드는 막대 그래프와 같은 'Figure 준비' -> '서브플롯 할당' -> '세부 설정' 순서로 작성했습니다.


첫번째 그래프인 계절별 대여 수량 박스플롯을 보겠습니다. 자전거 대여 수량은 봄에 가장 적고, 가을에 가장 많습니다. 두번째 박스플롯이 보여주는 날씨별 대여 수량은 우리의 직관과 일치합니다. 날씨가 좋을 때 대여 수량이 가장 많고, 안 좋을수록 수량이 적습니다. 폭우, 폭설 등에는 그래프의 가장 오른쪽 박스를 통해 대여 수량이 거의 없다는 점을 확인할 수 있습니다.
세번째 그래프는 공휴일 여부에 따른 대여 수량을 나타내는 박스폴롯입니다. x축 라벨 0일 공휴일이 아닌라는 뜻이며, 1은 공휴일이라는 뜻입니다. 공휴일일 때와 아닐 때 자전거 대여 수량의 중앙값은 거의비슷합니다. 다만, 공휴일이 아닐 때는 이상치가 많습니다. 네번째 그래프의 박스플롯 역시 마찬가지입니다. 근무일 여부에 따른 대여 수량을 의미하는데, 근무일일 때 이상치가 많습니다.
- 포인트플롯
다음으로 근무일, 공휴일, 요일, 계절, 날씨에 따른 시간대별 평균 대여 수량을 포인트플롯으로 그려보겠습니다. 포인트플롯은 범주형 데이터에 따른 수치형 데이터의 평균과 신뢰구간을 점과 선으로 표시합니다. 막대 그래프와 동일한 정보를 제공하지만, 한 화면에 여러 그래프를 그려 서로 비교하기에 더 적합하다는 특징이 있습니다.

모든 포인트플롯의 hue 파라미터에 비교하고 싶은 피처를 전달했습니다. hue 파라미터에 전달한 피처를 기준으로 그래프가 나뉩니다.
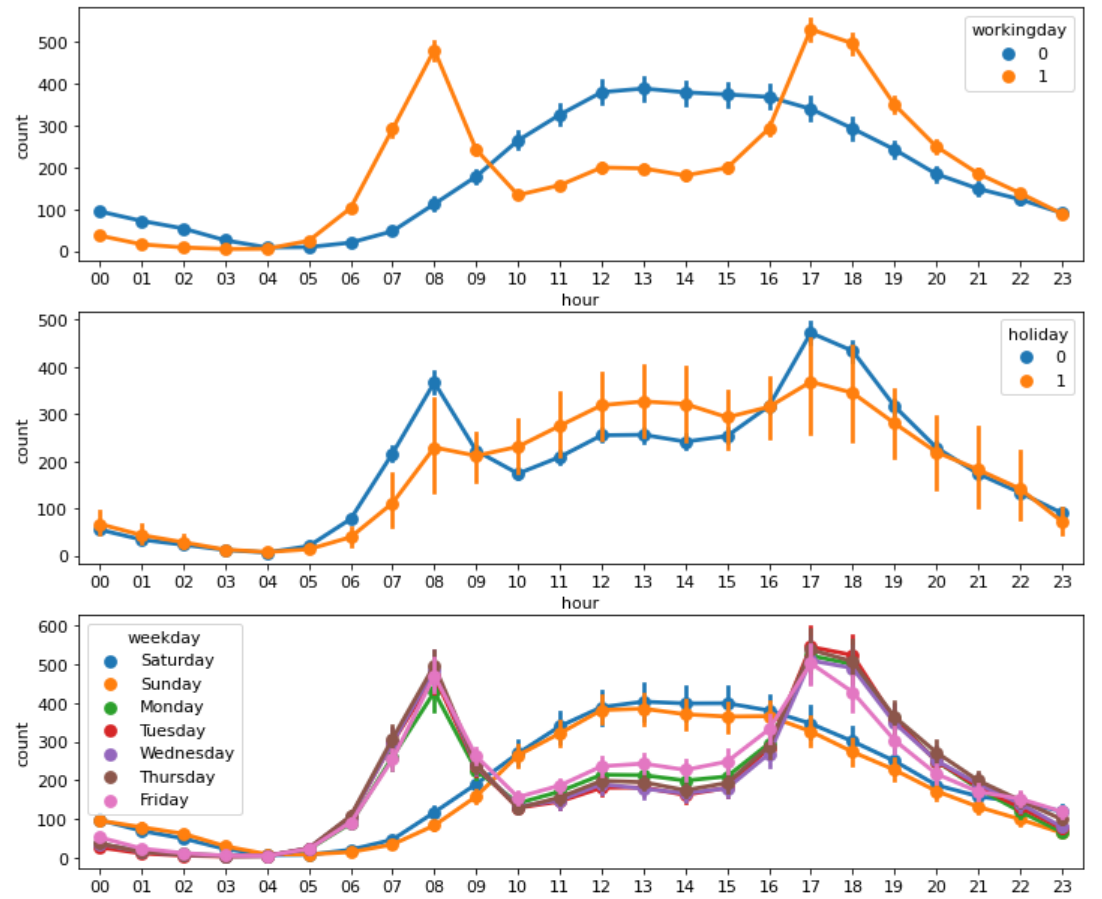
1번 그래프를 보면 근무일에는 출퇴근 시간에 대여 수량이 많고 쉬는 날에는 오후 12시부터~2시에 가장 많습니다. 2번 공휴일 여부, 3번 요일에 따른 포인트 플롯 역시 근무일 여부에 따른 포인트플롯, 즉 1번 그래프와 비슷한 양상을 보입니다.

4번 계절에 따른 시간대별 포인트 플롯을 보겠습니다. 대여 수량은 가을에 가장 많고, 봄에 가장 적습니다. 마지막 그래프는 날씨에 따른 시간대별 포인트 플롯입니다. 예상대로 날씨가 좋을 때 대여량이 가장 많았습니다. 그런데 폭우, 폭설이 내렸을 때, 18시에 자전거를 대여한 건수가 보입니다. 이런 이상치는 제거를 고려해보는 것도 괜찮은 방법입니다. 따라 추후 이 데이터는 제거해서 모델을 만들도록 하겠습니다.
| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
| 3. 연도, 시간, 월, 일, 시간, 분, 초 피처 추가 |
| 4. 요일 피처 추가 |
| 5. date 피처 제거 |
| 6. month 피처 제거 |
| 7. 타깃값을 count가 아닌 log(count)로 변환해 사용 |
| 8. 마지막에는 지수변환하여 count로 복원 |
| 9. day 피처 제거 |
| 10. minute, second 피처 제거 |
| 11. weaher == 4인 데이터 제거 |
- 회귀선을 포함한 산점도 그래프
수치형 데이터인 온도, 체감 온도, 풍속, 습도별 대여 수량을 '회귀선을 포함한 산점도 그래프'로 그려보겠습니다. 회귀선을 포함한 산점도 그래프는 수치형 데이터 간 상관관계를 파악하는데 사용합니다.
이 그래프는 seaborn의 regplot() 함수로 그릴 수 있습니다.

regplot()함수의 파라미터 중 scatter_kws={'alpha': 0.2}는 산점도 그래프에 찍히는 점의 투명도를 조절합니다. 즉 alpha를 0.2로 설정하면 평소에 비해 20% 수준으로 투명해집니다. alpha가 1에 가까울 수록 불투명하고 0에 가까울 수록 투명해집니다.
이어서 line_kws={'color': 'blue'}는 회귀선의 색상을 선택하는 파라미터입니다. 회귀선이 잘보이도록 그래프에 찍히는 점보다 짙은 색으로 설정했습니다.

회귀선 기울기로 대략적인 추세를 파악할 수 있습니다. 첫번째와 두번째 그래프부터 보면, 온도와 체감 온도가 높을 수록 대여 수량이 많은 것을 알 수 있습니다. 또한 네번째 그래프를 통해 습도는 낮을 수록 대여가 많은 것을 알 수 있습니다. 정리하다면 대여 수량을 추울 떄보다 따뜻할 때 많고, 습할 때보다 습하지 않을때 많다는 의미가 됩니다. 이는 우리의 직관과 일치합니다.
세번째 그래프를 확인해보겠습니다. 회귀선을 보면 풍속이 높을 수록 대여 수량이 많습니다. 우리의 직관으로 생각했을 땐, 바람이 약할 수록 대여 수량이 많을 것 같은데 이상합니다. 이 이유는 windspeed 피처에 결측치가 많기 때문입니다. 이는 그래프에도 명확히 나와있는데요. 풍속이 0인 데이터가 꽤 많습니다. 이것이 의미하는 바는 실제 풍속이 0이 아니라 관측치가 없거나 오류로 인해 0으로 기록됐을 가능성이 높습니다. 정리하자면 결측치가 많아서 그래프만으로 풍속과 대여수량의 상관관계를 파악하기는 힘듭니다. 결측값을 다른 값으로 대체하거나 windspeed 피처 자체를 삭제하는 방법 등으로 결측값이 많은 데이터는 적절히 처리 해야합니다. 이번에는 피처 자체를 삭제하도록 하겠습니다.
| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
| 3. 연도, 시간, 월, 일, 시간, 분, 초 피처 추가 |
| 4. 요일 피처 추가 |
| 5. date 피처 제거 |
| 6. month 피처 제거 |
| 7. 타깃값을 count가 아닌 log(count)로 변환해 사용 |
| 8. 마지막에는 지수변환하여 count로 복원 |
| 9. day 피처 제거 |
| 10. minute, second 피처 제거 |
| 11. weaher == 4인 데이터 제거 |
| 12. windspeed 피처 제거 |
- 히트맵
temp, atemp, humidity, windspeed, count 는 수치형 데이터 입니다. 수치형 데이터끼리 어떠한 상관관계가 있는지 살펴보도록 하겠습니다. corr() 함수는 DataFrame 내의 피처 간 상관계수를 계산해 반환합니다.

하지만 조합이 너무 많아 어니 피처들의 관계가 깊은지 한눈에 들어오지 않습니다. 히트맵이 이럴 경우에 필요합니다. 히트맵은 데이터 간 관계를 색상으로 표현하여, 여러 데이터를 한눈에 비교하기에 좋습니다. 히트맵은 seaborn의 heatmap()함수로 그릴 수 있습니다.

(1) 코드의 corr() 함수로 구한 상관관계 매트릭스 corrMat를 (2) heatmap() 함수에 인수로 넣어주면 됩니다. 이때 annot 파라미터를 True로 설정하면 상관계수가 숫자로 표시됩니다.
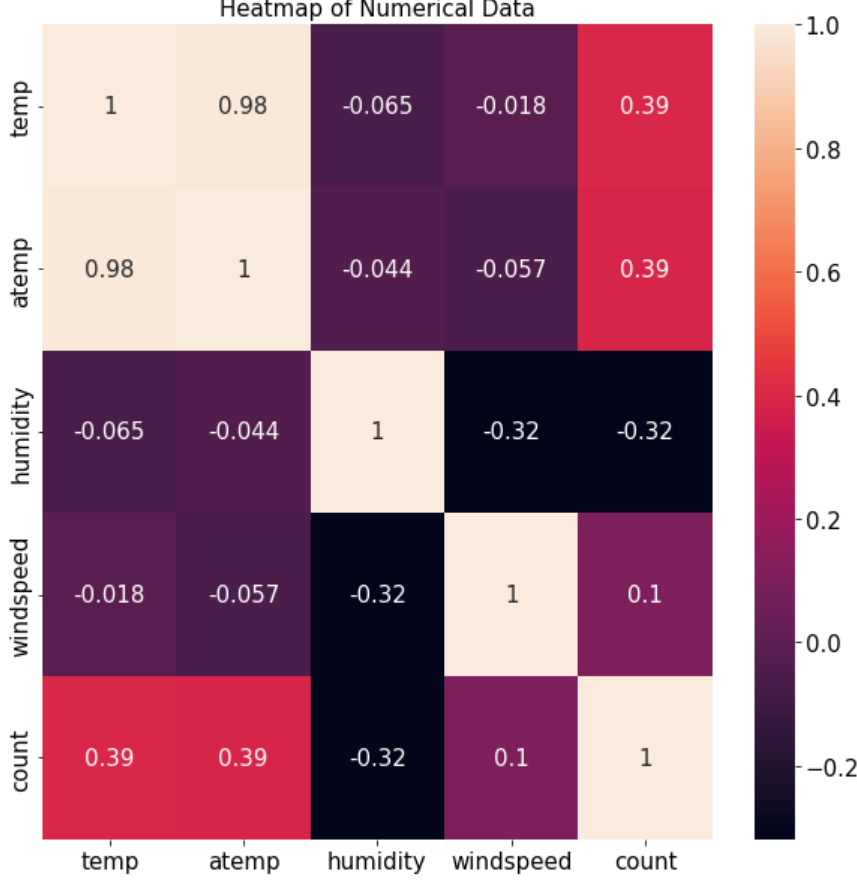
온도(temp)와 대여 수량(count) 간 상관계수는 0.39입니다. 양의 상관관계를 보입니다. 이는 온도가 높을수록 대여 수량이 많다는 의미 입니다. 반면, 습도(humidity)와 대여 수량은 음수이니 습도가 낮을수록 대여수량이 많다는 뜻입니다. 앞서 산점도 그래프에서 분석한 내용과 동일합니다.
풍속(windspeed)과 대여 수량의 상관계수는 0.1입니다. 상관관계가 매우 약합니다. 즉 windspeed 피처를 대여 수량 예측에 별 도움을 주지 못한다는 의미입니다. 따라 성능을 높이기 위해 모델링 시 windspeed 피처를 제거하겠습니다. (앞의 '회귀선을 포함한 산점도 그래프' 절에서는 결측값이 많다는 이유로 같은 결론에 도달했었습니다.)
| 분석 결과 |
| 1. casual, registered 피처 제거 |
| 2. datetime 피처 제거 |
| 3. 연도, 시간, 월, 일, 시간, 분, 초 피처 추가 |
| 4. 요일 피처 추가 |
| 5. date 피처 제거 |
| 6. month 피처 제거 |
| 7. 타깃값을 count가 아닌 log(count)로 변환해 사용 |
| 8. 마지막에는 지수변환하여 count로 복원 |
| 9. day 피처 제거 |
| 10. minute, second 피처 제거 |
| 11. weaher == 4인 데이터 제거 |
| 12. windspeed 피처 제거 (같은 결론, 두 가지 이유) |
3. 분석 정리
지금까지 다양한 측면에서 데이터를 살펴보았습니다. 분석 과정에서 파악한 주요 내용을 정리하면 다음과 같습니다.
1. 타깃값 변환 : 분포도 확인 결과 타깃값이 count가 0 근처로 치우쳐 있으므로 로그변환하여 정규분포에 가깝게 만들어야 합니다. 타깃값을 count가 아닌 log(count)로 변환해 사용할 것이므로 마지막에 다시 지수변환해 count로 복원해야 합니다.
2. 파생 피처 추가 : datetime 피처는 여러가지 정보의 혼합체이므로 각각을 분리해 year, month, day, hour, minute, second 피처를 생성할 수 있습니다.
3. 파생 피처 추가 : datetime 에 숨어 있는 또 다른 정보인 요일(weekday) 피처를 추가하겠습니다.
4. 피처 제거 : 테스트 데이터에 없는 피처는 훈련에 사용해도 큰 의미가 없습니다. 따라서 훈련 데이터에만 있는 casual과 registered 피처는 제거하겠습니다.
5. 피처 제거 : datetime 피처는 인덱스 역할만 하므로 타깃값 예측에 아무런 도움이 되지 않습니다.
6. 피처 제거 : date 피처가 제공하는 정보는 year, month, day 피처에 담겨 있습니다.
7. 피처 제거 : month는 season 피처의 세부 분류로 볼 수 있습니다. 데이터가 지나치게 세분화되어 있으면 분류별 데이터 수가 적어서 오히려 학습에 방해가 되기도 합니다.
8. 피처 제거 : 막대 그래프 확인 결과 파생 피처인 day는 분별력이 없습니다.
9. 피처 제거 : 막대 그래프 확인 결과 파생 피처인 minute와 second에는 아무런 정보가 담겨 있지 않습니다.
10. 이상치 제거 : 포인트 플롯 확인 결과 weather가 4인 데이터는 이상치 입니다.
11. 피처 제거 : 산점도 그래프와 히트맵 확인 결과 windspeed 피처에는 결측값이 많고 대여 수량과의 상관계수가 매우 약합니다.
'IT > 머신러닝&딥러닝' 카테고리의 다른 글
| [머신러닝/딥러닝] 향후 판매량 예측 (3)_모델 성능 개선 (0) | 2022.11.28 |
|---|---|
| [머신러닝/딥러닝] 향후 판매량 예측 (2)_베이스라인 모델 (0) | 2022.11.28 |
| [머신러닝/딥러닝] 안전 운전자 예측 (1) (0) | 2022.11.07 |
| [머신러닝/딥러닝]경진대회_범주형 데이터 이진분류(2) (0) | 2022.10.31 |
| [머신러닝/딥러닝] 데이터를 한눈에 주요 시각화 그래프 (0) | 2022.09.12 |



