<머신러닝. 딥러닝 문제해결 전략> 1부 4장을 정리한 내용입니다.
1. 데이터 종류
정형 데이터는 크게 수치형 데이터와 범주형 데이터로 나뉩니다.
| 대분류 | 소분류 | 예시 |
| 수치형 데이터 (사칙 연산이 가능한 데이터) |
연속형 데이터 | 키, 몸무게, 수입 |
| 이산형 데이터 | 과일 개수, 책의 페이지 수 | |
| 범주형 데이터 (범주로 나누어지는 데이터) |
순서형 데이터 | 학점, 순위(랭킹) |
| 명목형 데이터 | 성별, 음식 종류, 우편 번호 |
- 수치형 데이터
수치형 데이터는 사칙 연산이 가능한 데이터를 입니다. 이는 다시 연속형 데이터와 이산형 데이터로 나뉩니다.
연속형 데이터 : 값이 연속된 데이터 입니다.
예시로는 '키'와 같이 170cm와 171cm 사이에 170.1cm, 170.2cm, 170.9999cm 등 무한히 많은 값이 있습니다.
이렇게 값이 끊기지 않고 연속된 데이터를 연속형 데이터라고 합니다.
이산형 데이터 : 정수로 딱 떨어져 셀 수 있는 데이터 입니다.
예시로는 '과일 개수'와 같이 3개 4개 딱 떨어지는 데이터이며, 이는 '책의 페이지 수'도 마찬가지 입니다.
즉, 연속형 데이터는 실수로 표현할 수 있는 데이터, 이산형 데이터는 정수로 표현할 수 있는 데이터라고 할 수 있습니다.
- 범주형 데이터
범주형 데이터는 범주를 나눌 수 있는 데이터로, 사칙 연산이 불가능합니다. 또한 이는 다시 순서형 데이터와 명목형 데이터로 나뉩니다.
순서형 데이터 : 순위를 매길 수 있는 데이터 입니다.
예시로는 '학점'과 '메달'이 있으며, 학점의 경우는 A+, A0, A-, B+ 등 순위가 정해져 있습니다.
명목형 데이터 : 순위가 따로 없는 데이터 입니다.
예시로는 '성별'과 '우편번호'가 있습니다. 남자와 여자는 순위가 없습니다. 또한 우편번호는 숫자로 표현하지만 명목형 데이터입니다. 왜냐하면 순위도 없고, 우리집 우편번호와 옆집 우편번호를 더한다고 어떤 의미 있는 우편번호가 되지 않기 때문입니다.
이러한 범주형 데이터는 숫자로 되어 있다고 모두 수치형 데이터가 아님을 의미합니다.
2. 탐색적 데이터 분석과 그래프
탐색적 데이터 분석 단계에서는 다양한 그래프를 그립니다. 그래프는 데이터를 한눈에 파악하는데 도움을 주기 때문입니다. 이를 활용해 데이터가 어떻게 구성돼 있는지, 어떤 피처가 중요한지, 어떤 피처를 제거할지, 어떻게 새로운 피처를 만들지 등 모델링에 다양한 정보를 얻을 수 있습니다.
해당 책에서의 코드 예제는 matplotlib이 아닌 seaborn을 기준으로 했습니다. 둘 모두 파이썬으로 그래프를 그릴 때 흔히 사용하는 대표적인 시각화 라이브러리 입니다. 하지만 seaborn을 사용하면 더 간결하고, 기본 결정에서의 그래프가 좀 더 정결합니다.
3. 수치형 데이터 시각화
수치형 데이터는 일정한 범위 내에서 어떻게 분포되어 있는지가 중요합니다. 고르게 퍼져 있을 수도, 특정 영역에 몰려 있을 수 도 있습니다. 이 분포를 알아야 데이터를 어떻게 변환할지, 어떻게 해석해서 활용할지 판단할 수 있습니다.
이는 이번의 모든 예시 코드 앞에 생략된 2줄로, seaborn을 import 하고 데이터를 불러오는 코드입니다.

titanic은 seaborn에서 제공하는 데이터로, 데이터의 구성은 다음과 같습니다.
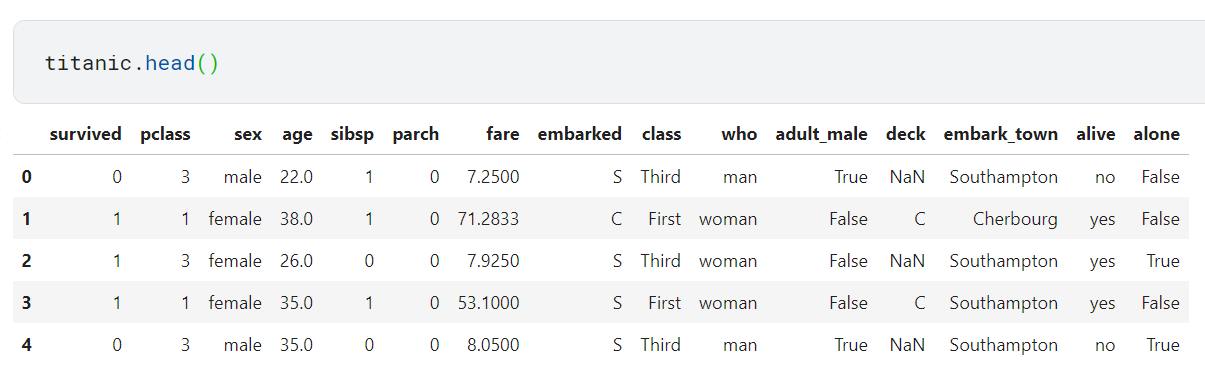
이를 살펴보면 수치형 데이터(age, fare 등)와 범주형 데이터(sex, embarked, class 등)가 공존하고 있는 것을 알 수 있습니다.
다음은 seaborn이 제공하는 주요 분포도 함수로써, 수치형 데이터를 시각화 하는데 사용됩니다.
histplot() : 히스토그램
kdeplot() : 커널밀도추정 함수 그래프
displot() : 분포도
rugplot() : 러그플롯
이를 차례대로 살펴보도록 하겠습니다.
- 히스토그램(histplot)
히스토그램은 수치형 데이터의 구간별 빈도수를 나타내는 그래프입니다. histplot()함수로 그릴 수 있습니다.
titanic 데이터의 age 피처에 대한 히스토그램을 그려보겠습니다.그리기 위해서는 histplot()의 data 파라미터에 전체 데이터셋을 DataFramge 형식으로 전달하고, x 파라미터에 분포를 파악하려는 피처를 전달하면 됩니다.
해당 코드와 해당 코드의 결과는 다음과 같습니다.

다음과 같이 잘 그려진 것과 구간 개수를 지정하는 bins 파라미터의 기본값을 설정하지 않아 총 20개의 구간으로 결과가 나온 것을 확인 할 수 있습니다. 만약, 구간을 10개로 고정하고 싶다면 다음과 같이 bins=10을 전달하면 됩니다.
해당 코드와 해당 코드의 결과는 다음과 같습니다.

히스토그램은 기본적으로 수치형 데이터 하나에 대한 빈도를 나타냅니다. 여기서 해당 빈도를 특정 범주별로도 구분해서 보고 싶다면, hue 파라미터에 해당 범주형 데이터를 전달하면 됩니다. 다음은 생존여부 (alive 피처)에 따른 연령 분포를 그려주는 코드입니다.
해당 코드와 해당 코드의 결과는 다음과 같습니다.
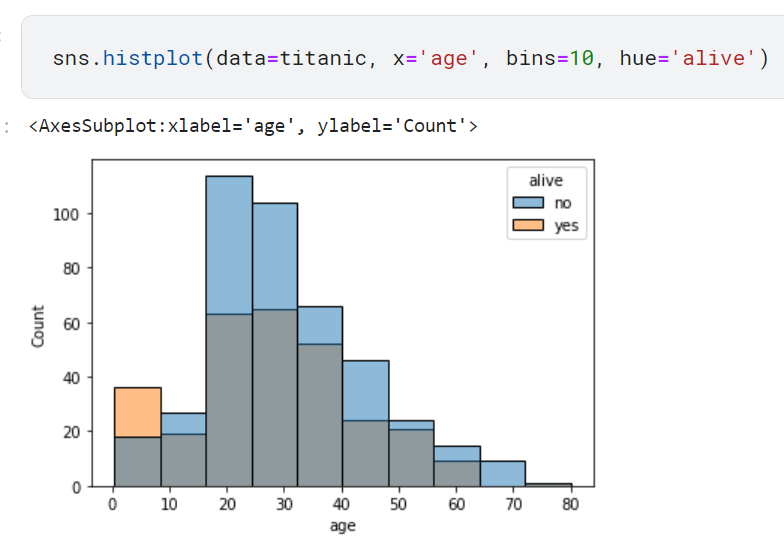
보이는 것처럼 생존자 수 그래프와 사만자 수 그래프를 포개지게 그렸습니다. 회색 구간이 두 그래프가 서로 겹친 부분입니다. 포개지 않고 생존자 수와 사망자 수를 누적해 포현하려면 multiple='stack'을 전달하면 됩니다.
해당 코드와 해당 코드의 결과는 다음과 같습니다.

- 커널밀도추정 함수 그래프(kdeplot)
커널밀도추정 함수는 쉽게 생각해 히스토그램을 매끄럽게 곡선으로 연결한 그래프로 이해하면 됩니다. 커널밀도추정 함수그래프는 kdeplot()로 그릴 수 있는데, 실제로 탐색적 분석 시 많이 쓰지는 않습니다.
커널밀도추정 함수의 코드와 해당 코드의 결과는 다음과 같습니다.
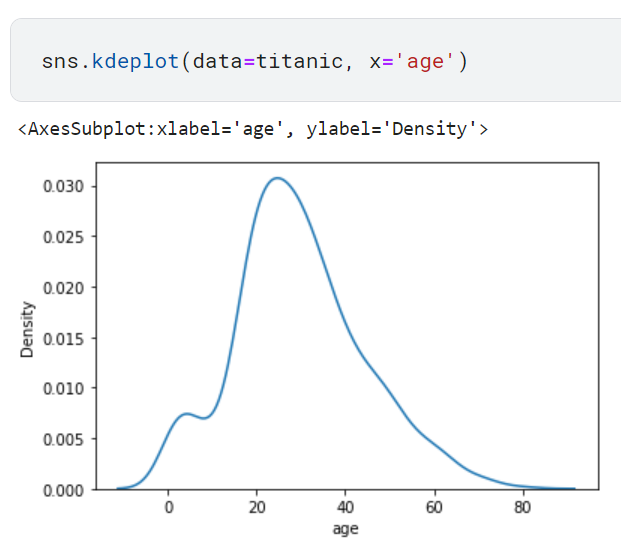
이는 앞서 그린 히스토그램과 비교했을때, 이를 매끄럽게 연결한 모양입니다. 즉 히스토그램은 이산적이지만, 커널밀도추정 함수 그래프는 연속적이라는 말과 같습니다.
파라미터로 hue='alive'와 multiple='stack'을 전달하면 다음과 같이 바뀝니다. 해당 코드와 해당 코드의 결과는 다음과 같습니다.
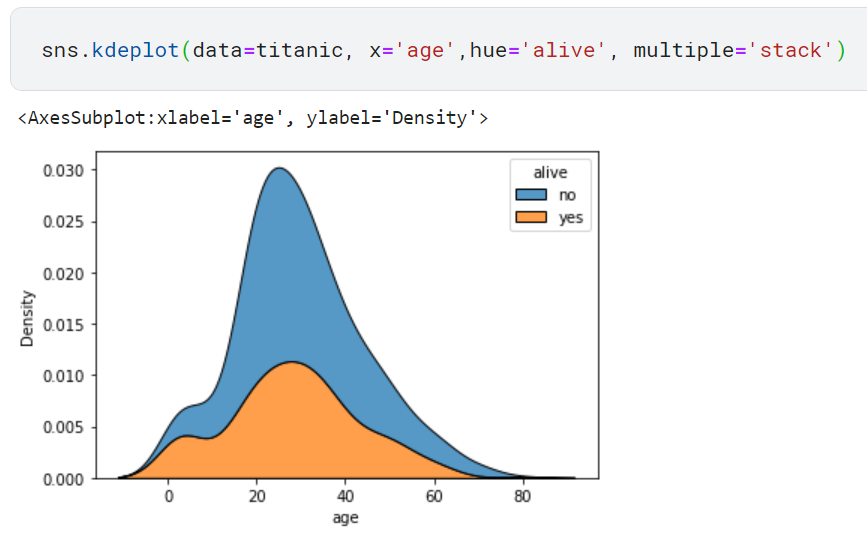
이 역시 앞서 본 누적 히스토그램과 비교하면 이산적인지 연속적인지 차이가 있을뿐 전체적인 모양새는 거의 같다는 것을 알 수 있습니다.
- 분포도(displot)
분포도는 수치형 데이터 하나의 분포를 나타내는 그래프입니다.
캐글에서 분포도를 그릴 땐 displot()을 많이 사용합니다. 왜냐하면 파라미터만 조정하면 histplot()과 kdeplot()이 제공하는 기본 그래프를 모두 그릴 수 있습니다.
파라미터를 기본값으로 두면 히스토그램을 그립니다.해당 코드와 해당 코드의 결과는 다음과 같습니다.

앞서 histsplot()이 그린 히스토그램과 비교하면 크기만 다를 뿐 같은 그래프 라는 것을 알 수 있습니다.
커널밀도추정 함수 그래프를 기리기 위해서는 kind 파라미터에 'kde'를 전달하면 됩니다. 해당 코드와 해당 코드의 결과는 다음과 같습니다.
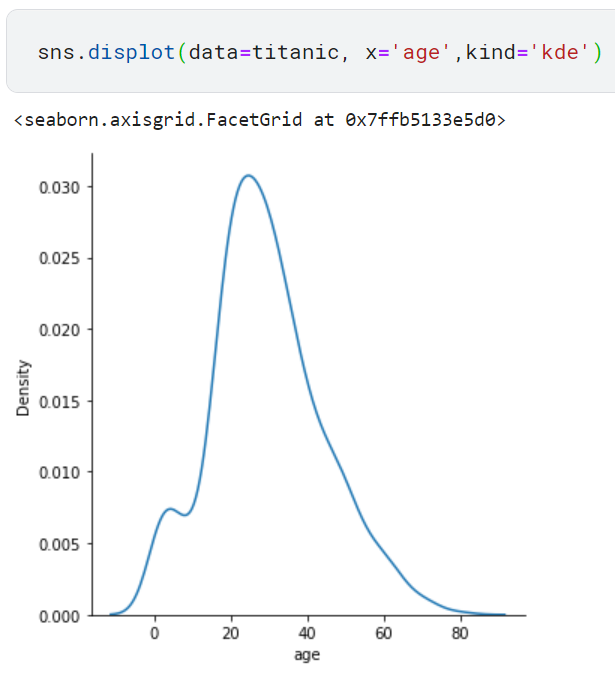
이번에도 kdeplot()으로 그린 결과와 그래프 크기만 다르다는 것을 알 수 있습니다.
히스토그램과 커널밀도추정 함수 그래프를 동시에 그릴 수도 있습니다. 이는 kde 파라미터를 True로 전달하면 됩니다.해당 코드와 해당 코드의 결과는 다음과 같습니다.

- 러그플롯(rugplot)
러그플롯은 주변 분포를 나타내는 그래프입니다. 단독으로 사용하기보다는 주로 다른 분포도 그래프와 함께 사용됩니다.
다음은 커널밀도추정 함수 그래프와 러그플롯을 함께 그린 예시입니다.해당 코드와 해당 코드의 결과는 다음과 같습니다.

이렇듯 러그플롯은 단일 피처 (여기서는 age 피처)가 어떻게 분포되어 있는지를 x축 위에 작은 선분(러그)으로 표시합니다. 값이 밀집돼 있을수록 작은 선분들도 밀집돼 있습니다.
4. 범주형 데이터 시각화
범주형 데이터를 시각화하는 방법을 알아보겠습니다. 이번 절에도 타이타닉 데이터를 활용하며, 다음과 같은 코드가 생략되었습니다.
막대 그래프, 포인트플롯, 박스플롯, 바이올린플롯, 카운트플롯을 차례대로 살펴보겠습니다.
- 막대 그래프(barplot)
막대 그래프는 범주형 데이터 값에 따라 수치형 데이터 값이 어떻게 달라지는지 파악할 때 사용합니다. 이는 barplot()으로 그릴 수 있습니다.
barplot()은 범주형 데이터에 따른 수치형 데이터의 평균과 신뢰구간을 그려줍니다. 수치형 데이터 평균은 막대 높이로, 신뢰구간은 오차 막대로 표현합니다. 원본 데이터를 복원 샘플링하여 얻은 표본을 활용해 평균과 신뢰구간을 구하는 것입니다. 즉, barplot()은 원본 데이터 평균이 아니라 샘플링한 데이터 평균을 구해줍니다.
기본적으로 x 파라미터에 범주형 데이터를, y 파라미터에 수치형 데이터를 전달합니다. data 파라미터에는 전체 데이터 셋을 전달합니다.
타이타닌 탑승자 등급별 운임을 barplot()으로 그려보겠습니다. 범주형 데이터인 class(등급) 피처를 x 파라미터에, 수치형 데이터인 fare(운임)피처를 y 파라미터에 전달했습니다.
해당 코드와 해당 코드의 결과는 다음과 같습니다.

막대 높이는 등급별 평균 운임을 뜻합니다. 막대 상단의 검은색 세로줄이 오차 막대(신뢰구간)입니다. 등급이 높을수록 평균 운임이 비싸고 신뢰구간이 넓어지는 것을 알 수 있습니다.
- 포인트플롯(pointplot)
포인트플롯은 막대 그래프와 모양만 다를 뿐 동일한 정보를 제공합니다. 막대 그래프와 마찬가지로 범주형 데이터에 따른 수치형 데이터의 평균과 신뢰구간을 나타냅니다. 차이점이 있다면 이는 그래프를 점과 선으로 나타낸다는 특징이 있습니다.
타이타닉 탑승자 등급별 운임을 pointplot()으로 그려보겠습니다.해당 코드와 해당 코드의 결과는 다음과 같습니다.

보이는 것처럼 포인트플롯과 막대 그래프는 동일한 정보를 제공합니다. 그러면 언제 포인트플롯을 사용하는 게 좋을까요? 이는 한 화면에서 여러 그래프를 그릴 때 입니다. 포인트플롯은 점과 선으로 표현하기에 여러 그래프를 그려도 서로 잘 보이고, 비교하기도 쉽습니다.
- 박스플롯(boxplot)
박스플롯은 막대 그래프나 포인트플롯보다 더 많은 정보를, 구체적으로 5가지 요약 수치를 제공합니다. 5가지 요약 수치는 최솟값, 제1사분위 수(Q1), 제2사분위 수(Q2), 제3사분위 수(Q3), 최댓값을 뜻합니다.
제1사분위 수(Q1) : 전체 데이터 중 하위 25%에 해당하는 값
제2사분위 수(Q2) : 50%에 해당하는 값(중앙값)
제3사분위 수(Q3) : 상위 25%에 해당하는 값
사분위 범위 수(IQR) : Q3 - Q1
최댓값 : Q3 + (1.5 * IQR)
최솟값 : Q1 - (1.5 * IQR)
이상치 : 최댓값보다 큰 값과 최솟값보다 작은 값

박스플롯은 boxplot()으로 그릴 수 있습니다. 타이타닉 탑승자 등급별 나이를 박스플롯으로 그려보겠습니다. boxplot()의 x, y 파라미터에 각각 범주형 데이터(class)와 수치형 데이터(age)를 전달합니다.
해당 코드와 해당 코드의 결과는 다음과 같습니다.

- 바이올린플롯(violinplot)
바이올린플롯은 박스플롯과 커널밀도추정 함수 그래프를 합쳐 놓은 그래프라고 볼 수 있습니다. 박스플롯이 제공하는 정보를 모두 포함하며, 모양은 커널밀도추정 함수 그래프 형태입니다.
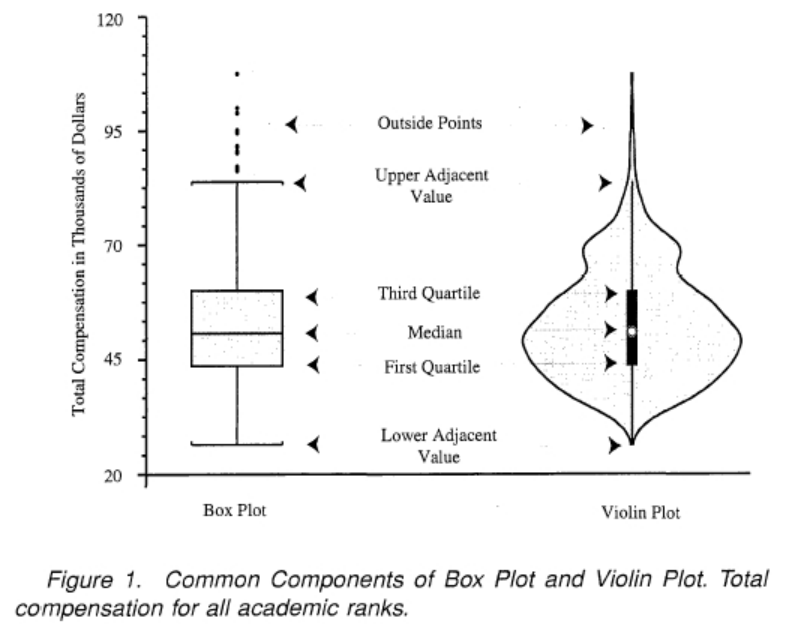
바이올린플롯은 violinplot()으로 그릴 수 있습니다. 앞의 박스플롯과 비교해보기 위해 똑같이 등급(class)별 나이(age)를 그려보겠습니다.해당 코드와 해당 코드의 결과는 다읍과 같습니다.

박스 플롯 그래프와 비교했을땨, 각 범주별로 5가지 요약 수치를 한눈에 보고 싶다면 박스플롯이 수치형 데이터의 전체적인 분포 양상을 알고 싶다면 바이올린플롯이 더 좋다는 점을 알 수 있습니다.
이어서 성별에 따른 등급별 나이 불포를 살펴보겠습니다. hue='sex'를 추가로 전달하면 됩니다. 또한 split = True를 전달하면 hue에 전달한 피처를 반으로 나누어 보여줍니다. 해당 코드와 해당 코드의 결과는 다음과 같습니다.

- 카운트플롯(countplot)
카운트플롯은 범주형 데이터의 개수를 확인할 때 사용하는 그래프입니다. 주로 범주형 피처나 범주형 타깃값의 분포가 어떤지 파악하는 용도로 사용됩니다.
카운트플롯은 countplot()으로 그릴 수 있습니다. x 파라미터에 범주형 데이터를 전달하면 됩니다. 타이타닉 탑승자의 등급별 인원수를 카운트 플롯으로 그려보겠습니다.해당 코드와 해당 코드의 결과는 다음과 같습니다.
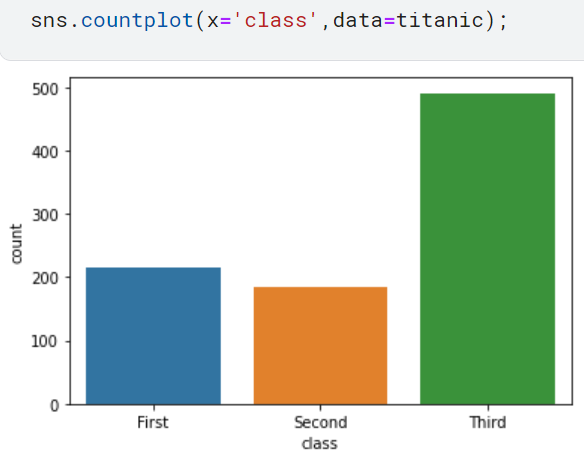
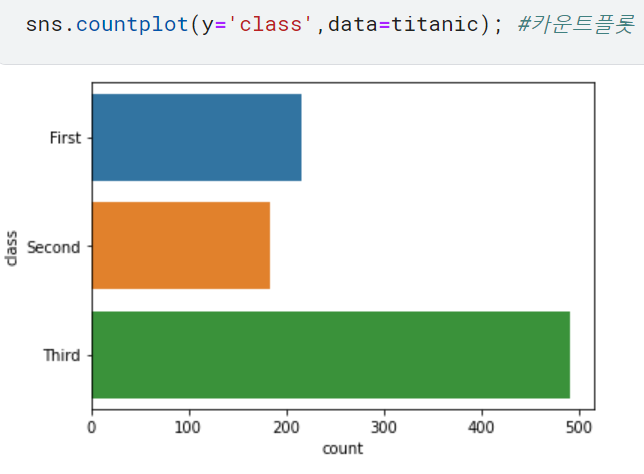
이렇듯 카운트플롯을 사용하면 범주형 데이터의 개수를 파악할 수 있습니다.또한, x 파라키터를 y로 바꾸면 다음과 같이 그래프 방향을 바꿀 수 있습니다.해당 코드와 해당 코드의 결과는 다읍과 같습니다.

범주형 데이터 개수가 많아 그래프가 옆으로 너무 넓어져 보기 불편할 경우 유용하게 사용됩니다.
- barplot() vs. countplot()
막대 그래프를 그려주는 barplot()과 카운트플롯을 그려주는 countplot()은 비슷한 듯 보이지만 서로 다릅니다.
barplot()은 범주형 데이터별 수치형 데이터의 평균을 구해주기 때문에 피처를 두 개 받습니다.

반면 countplot()은 피처를 범주형 데이터 하나만 받습니다.
한편 barplot()으로는 평균이 아닌 중앙값, 최댓값, 최솟값을 구할 수도 있습니다.
중앙값의 경우

최댓값의 경우
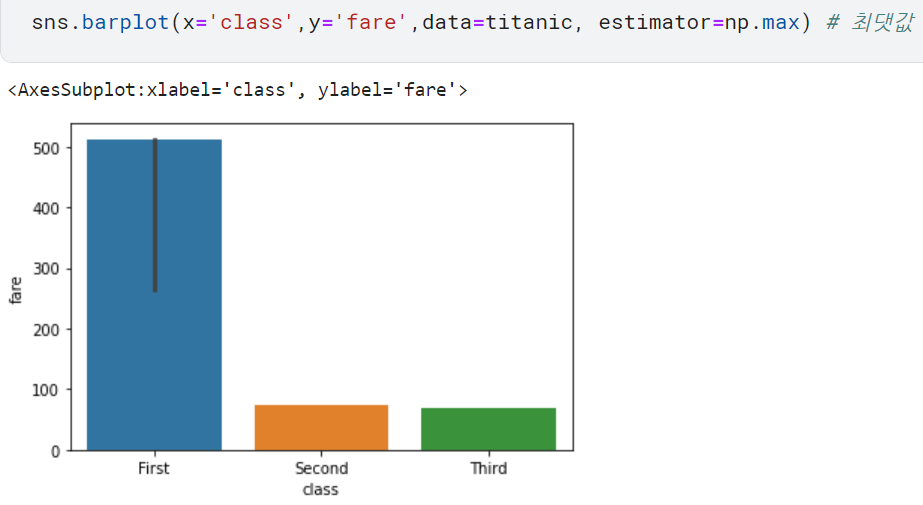
최솟값의 경우

- 파이 그래프(pie)
파이 그래프는 범주형 데이터별 비율으 알아볼 때 사용하기 좋은 그래프입니다. seaborn에서는 파이 그래프를 지원하지 않기에 matplotlib을 사용해야합니다.
파이 그래프는 pie()함수로 그릴 수 있습니다. x 파라미터에는 비율을, labels 파라미터에는 범주형 데이터 레이블명을 전달하면 됩니다. 또한, autopct 파라미터를 통해 비율을 숫자로 나타낸 수 있습니다.해당 코드와 해당 코드의 결과는 다음과 같습니다.

5. 데이터 관계 시각화
관계도는 여러 데이터 사이의 관계를 살펴보기 위한 그래프입니다.
히트맵, 라인플롯, 산점도, 회귀선을 포함한 산점도를 살펴보겠습니다.
- 히트맵(heatmap)
히트맵은 데이터 간 관계를 색상으로 표현한 그래프입니다. 비교해야 할 데이터가 많을 때 주로 사용하며, heatmap()함수를 이용합니다.
이번에 사용하는 데이터는 비행기 탑승자 수 데이터 입니다. 이는 연도별, 월별 탑승자 수를 나타내는 데이터 입니다.먼저, 데이터를 불러옵니다.

flights 데이터는 다음과 같이 구성되어 있습니다.

이를 통해 범주형 데이터 2개(year, month)와 수치형 데이터 1개(passengers)가 있는 것을 알 수 있습니다.
하지만 히트맵을 그리는데 활용하려면 판다스의 pivot()함수를 활용해서 데이터 구조를 조금 바꿔야만 합니다. pivot()함수는 index와 columns 파라미터에 전달한 피처를 각각 행과 열로 지정하고, values 파라미터에 전달한 피처를 합한 표를 반환합니다.
각 연도의 월별 승객 수를 알고 싶으니 , month를 행으로 year를 열로, 합산할 데이터를 passengers로 지정하겠습니다.해당 코드와 코드의 결과는 다음과 같습니다.

다음과 같이 각 연도의 월별 탑승자 수를 나타내는 표가 만들어졌습니다. 하지만 숫자로만 나열되니 추이까지는 한눈에 파악하기 어렵습니다. 이럴 때 사용하는 그래프가 히트맵으로, flight_pivot 데이터를 히트맵으로 표현하면 다음과 같습니다.해당 코드와 코드의 결과는 다음과 같습니다.

이렇게 히트맵으로 그리니 전체적인 양상을 쉽게 파악하기가 쉽습니다.
- 라인플롯(lineplot)
라인플롯은 두 수치형 데이터 사이의 관계를 나타낼 때 사용합니다. 기본적으로는 x 파라미터에 전달한 값에 따라 y 파라미터에 전달한 값의 평균과 95% 신뢰구간을 나타냅니다.코드와 해당 코드의 결과는 다음과 같습니다.

이때, x축은 연도, y축은 평균 승객수를 나타냅니다. 해가 갈수록 평균 승객수가 많아진다는 것을 알 수 있습니다. 실선 주변의 음영은 95% 신뢰구간 입니다.
- 산점도(scatterplot)
산점도는 두 데이터의 관계를 점으로 표현하는 그래프입니다. 산점도 그래프에는 총 비용과 팁 정보를 모아둔 tips 데이터셋을 활용합니다.

해당 데이터는 다음과 같이 구성되어 있습니다.

이 데이터의 산점도를 그리는 코드와 해당 결과는 다음과 같습니다.

대체로 총액이 늘면 팁도 따라서 늘고 있습니다.
다음과 같이 hue 파라미터를 이용하면 산점도를 특정 범주형 데이터별로 나누어 그릴 수 있습니다.다음 그래프는 시간(time) 에 따라 나눈 그래프 입니다.해당 코드와 해당 코드의 결과는 다음과 같습니다.
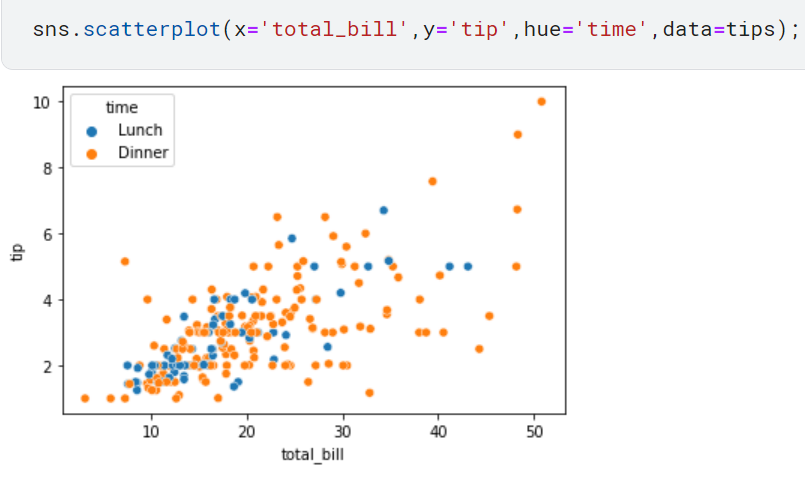
점심과 저녁으로 구분하였으나, 전체적인 추이는 비슷하다는 것을 알 수 있습니다.
- 회귀선을 포함한 산점도 그래프(regplot)
regplot()은 산점도와 선형 회귀선을 동시에 그려주는 함수 입니다. 회귀선을 그리면 전반적인 상관관계 파악이 좀 더 쉽습니다. 이번에도 tips 데이터를 활용해 그래프를 그리겠습니다.코드와 해당 코드의 결과는 다음과 같습니다.

보다시피 산점도와 함께 선형 회귀선이 나타났습니다. 선형 회귀선 주변 음영은 95% 신뢰구간을 의미합니다. 신뢰구간을 99%로 늘리려면 ci 파라미터에 99를 전달하면 됩니다.해당 코드와 해당 코드의 결과는 다음과 같습니다.

다음과 같이 99% 신뢰구간으로 설정하니 음영 부분이 더 넓어진 것을 확인할 수 있습니다.
'IT > 머신러닝&딥러닝' 카테고리의 다른 글
| [머신러닝/딥러닝] 향후 판매량 예측 (3)_모델 성능 개선 (0) | 2022.11.28 |
|---|---|
| [머신러닝/딥러닝] 향후 판매량 예측 (2)_베이스라인 모델 (0) | 2022.11.28 |
| [머신러닝/딥러닝] 안전 운전자 예측 (1) (0) | 2022.11.07 |
| [머신러닝/딥러닝]경진대회_범주형 데이터 이진분류(2) (0) | 2022.10.31 |
| [머신러닝/딥러닝] 경진대회_자전거 대여 수요 예측 (1) (0) | 2022.09.25 |



