[AWS Data Engineering] 9장 데이터 마트에 데이터 로드
<Data Engineering with AWS>의 9장 내용을 번역 및 요약 정리한 내용입니다.
https://www.amazon.com/Data-Engineering-AWS-Gareth-Eagar/dp/1800560419
Amazon.com
Enter the characters you see below Sorry, we just need to make sure you're not a robot. For best results, please make sure your browser is accepting cookies.
www.amazon.com
데이터 레이크를 사용할 경우 많은 양의 데이터 분석이 가능하지만, 데이터 엔지니어의 경우 데이터 소비자들을 위해 데이터 레이크에서 데이터 웨어하우스 혹은 데이터 마트로 보내야하는 경우도 존재합니다.
데이터 레이크의 경우 전체적인 비즈니스에 필요한 데이터가 담겨있는 단일 정보 소스라면, 데이터 마트는 특정 사용자 그룹이 관심을 갖는 부분적인 데이터들의 집합으로 구성되어있습니다. 또한 데이터 마트의 경우, 관계형 데이터베이스, 데이터 웨어하우스 혹은 또 다른 종류의 데이터 저장소입니다.
데이터 마트의 두 가지 주 사용 용도는 다음과 같습니다.
- 특정 유형의 쿼리에 최적화된 데이터 레이크의 데이터 하위 집합을 데이터베이스에 제공하는 것
- 특정 분석 사용에 필요한 고성능, 짧은 대기 시간 쿼리 엔진을 제공하는 것
따라 이번에는 데이터 웨어하우스 및 데이터 마트에 초점을 맞춰 다음과 같은 주제를 다룹니다.
1.데이터 웨어하우스/데이터 마트로 분석 확장
2.하지 말아야 할 것 - 데이터 웨어하우스 안티패턴
3. Redshift 아키텍처 검토 및 스토리지 심층 분석
4.고성능 데이터 웨어하우스 설계
5.데이터 레이크와 Redshift 간에 데이터 이동
1. 데이터 웨어하우스/데이터 마트로 분석 확장
Amazon Athena 와 같은 도구를 사용하면 데이터 레이크의 데이터에서 직접 SQL 쿼리를 실행할 수 있습니다. 이를 통해 Amazon S3 에 있는 매우 큰 데이터 세트를 쿼리할 수 있지만, 일반적으로 로컬에 위치한 성능이 고성능인 디스크의 데이터에 대해 쿼리를 실행할 때에 비해서는 성능이 떨어진다는 단점이 존재합니다. 따라 쿼리와 데이터를 세 가지 범주로 나눠 성능을 개선시켜야 합니다.
1.1 Cold Data
자주 액세스하지 않는 데이터이지만 규정 준수 및 거버넌스의 이유로 장기간 저장해야 하거나 향후 연구 및 개발을 위해 저장되는 기록 데이터입니다.
다음과 같은 S3 스토리지 클래스는 일반적으로 Cold Data에 사용되며, S3 수명 주기 규칙을 사용하여 특정 시간 후에 자동으로 해당 클래스로 데이터를 이동하게 할 수도 있습니다.
- Amazon S3 Glacier (S3 Glacier): 데이터에 대한 액세스가 1년에 몇 번 필요할 수 있고 즉각적인 액세스가 필요하지 않은 장기 스토리지에 해당됩니다. 특징으로 S3 Glacier에서 데이터 검색할 경우, 몇 분에서 몇 시간이 소요 된다는 점, S3 Glacier의 데이터는 Amazon Athena 또는 Glue 작업 으로 직접 쿼리할 수 없기 때문에 쿼리하기 전에 일반 스토리지 클래스에 저장하는 과정이 필요하다는 점이 있습니다.
- Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive): 장기 데이터 보존을 위한 가장 저렴한 스토리지이며 ,1년에 1~2회 밖에 검색할 필요없는 데이터를 위해 사용됩니다. 특징으로 S3 Glacier Deep Archive에서 데이터를 검색할 경우, 데이터는 12시간 내로 검색된다는 점이 존재합니다.
1.2 Warm Data
상대적으로 자주 액세스되지만 검색을 할 때 짧은 대기 시간이 필요하지 않은 데이터입니다.
다음과 같은 S3 스토리지 클래스는 Warm Data 에 일반적으로 사용됩니다.
- Amazon S3 Standard (S3 Standard): Amazon Athena 또는 Redshift Spectrum을 사용한 임시 SQL 쿼리 및 ETL 작업에 이상적인 성능으로 데이터에 대한 즉각적인 액세스를 제공합니다. 비용은 저장된 데이터 양을 기준으로 하며 GB당 데이터 검색 비용은 없습니다.
- Amazon S3 Standard-Infrequent Access (S3 Standard-IA): Amazon S3 Standard와 같이 빠른 검색 속도뿐만 아니라 데이터에 대한 즉각적인 액세스도 역시 제공합니다. 또한 Glue 작업, Amazon Athena, Redshift Spectrum 등을 통해 직접 액세스할 수 있습니다. 하지만 S3 Standard-IA를 사용하면 스토리지에 대한 GB당 비용은 S3 Standard보다 낮지만 데이터 검색에 대한 GB당 비용이 발생합니다.
- Amazon S3 Intelligent-Tiering (S3 Intelligent Tiering): 해당 스토리지 클래스는 데이터 액세스 패턴이 확실하지 않을 때 유용합니다. 지능형 계층화를 사용하면 데이터 개체가 30일 동안 액세스되지 않은 경우 데이터가 자동으로 표준 계층에서 Infrequent Access 계층으로 이동됩니다. 또한 선택적으로 아카이브 계층화도 활성화할 수 있으며, 이 경우 90일 동안 액세스하지 않은 객체는 S3 Glacier로 이동되고 액세스 없이 연속 180일 후에는 S3 Glacier Deep Archive로 이동됩니다. 또한 검색된 데이터에 대해 GB당 비용이 없지만 객체당 작은 모니터링 및 자동화 비용이 발생된다는 특징이 있습니다.
1.3 Hot Data
조직의 일상적인 분석 지원에 매우 중요한 데이터로, 하루에 여러 번 액세스할 가능성이 존재하고 데이터에 대한 짧은 대기 시간, 고성능 액세스가 중요한 데이터입니다.
일반적으로 Amazon Redshift 또는 Amazon QuickSight 가 사용됩니다.
- Amazon Redshift : 데이터 웨어하우스에 저장된 데이터에 대해 지연 시간이 짧은 고성능 액세스를 제공하는 초고속 클라우드 네이티브 데이터 웨어하우징 솔루션입니다.
- Amazon QuickSight : 대시보드 생성을 위한 Amazon의 비즈니스 인텔리전스 도구입니다. Amazon QuickSight를 사용하면 Amazon Redshift와 같은 소스에서 데이터를 읽거나 데이터를 QuickSight 인 메모리 데이터베이스 엔진으로 직접 로드하여 최적의 고성능, 짧은 지연 시간 액세스를 선택할 수 있습니다.
이와 같이 AWS는 다양한 데이터 유형를 위해 특별히 구축된 스토리지 엔진을 제공합니다. 따라 비용과 성능의 비교를 통해 사용할 엔진을 결정하는 것이 중요합니다.
2. 하지 말아야 할 것 - 데이터 웨어하우스의 안티패턴
분석을 위해 조직이 피해야 할 데이터 웨어하우스 사용 방법의 일부에 대해 알아보겠습니다.
2.1 데이터 웨어하우스를 트랜잭션 데이터 저장소로 사용
데이터 웨어하우스에는 데이터를 업데이트하거나 삭제하는 메커니즘이 존재하지만, 기본적으로 추가 전용 쿼리용으로 설계되었습니다. 따라 데이터 웨어하우스는 OLAP (온라인 분석 처리) 쿼리 에 최적화되도록 설계되었으므로 OLTP (온라인 트랜잭션 처리) 쿼리 및 사용 사례 에 사용해서는 안 됩니다.
2.2 데이터 웨어하우스를 데이터 레이크로 사용
데이터 웨어하우스는 고성능 스토리지를 컴퓨팅 엔진에 직접 연결하여 향상된 성능을 제공합니다. 데이터 웨어하우스는 또한 방대한 양의 데이터를 저장하도록 확장할 수 있으며 기본적으로 구조화된 데이터를 지원하도록 설계되었지만 반구조화된 데이터도 일부 지원합니다.
그러나 데이터 웨어하우스는 설계상 스키마 및 테이블 구조에 대한 사전 고려가 필요합니다. 또한 구조화되지 않은 데이터를 저장하도록 설계되지 않았으며 데이터 쿼리 및 변환을 위한 SQL만 지원합니다. 하지만 데이터 레이크의 경우 모든 데이터를 저장할 수 있으며 먼저 적절한 스키마 구조를 설계할 필요 없이 데이터를 수집할 수 있습니다.
따라 데이터 웨어하우스의 경우 불필요한 데이터를 저장하지 않는 것을 목표로 데이터 레이크와는 달리 데이터 세트를 직접 분석하고 다양한 도구를 사용하여 데이터를 변환한 다음 필요한 데이터만 데이터 웨어하우스에 저장해야 합니다.
2.3 실시간 레코드 수준 사용 사례에 데이터 웨어하우스 사용
데이터 웨어하우스는 데이터를 일괄적으로 로드하는데 최적화되어 있으며, 데이터를 개별 레코드로 수집하는 데 적합하지 않습니다. 따라 대량의 IoT 데이터와 같은 실시간 데이터 소스에 직접적인 대상으로 사용되어서는 안 됩니다.
2.4 구조화되지 않은 데이터 저장
일부 데이터 웨어하우스는 반정형 데이터를 지원하긴 하지만 이미지, 비디오 및 기타 미디어 콘텐츠와 같은 비정형 데이터를 저장하는 데 사용해서는 안 됩니다. 따라 데이터 웨어하우스에 데이터를 저장하는 것을 기본 설정하기 전에 특정 데이터 유형에 가장 적합한 데이터 엔진이 무엇인지 고려하는 과정이 필요합니다.
3. Redshift 아키텍처 검토 및 스토리지 심층 분석
3.1 슬라이스 간 데이터 분포
Redshift의 여러 조각에 데이터가 분산되는 방식입니다.
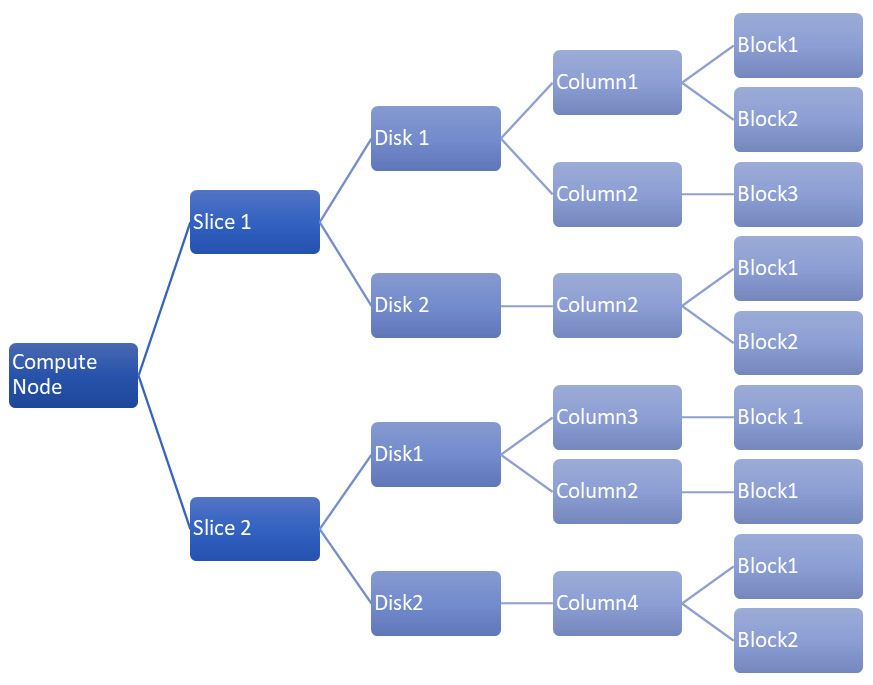
위의 다이어그램에서 column2가 Slice1-Disk1 , Slice1-Disk2 및 Slice2-Disk1 에 분산되어 있음 을 알 수 있습니다 .
데이터 처리량과 쿼리 성능을 높이려면 I/O 병목 현상을 방지하기 위해 슬라이스 전체에 데이터를 고르게 분산시켜야 합니다. 대부분의 경우 특정 테이블에 대한 데이터 중 하나가 하나의 노드에 있는 경우 해당 노드는 결국 모든 무거운 작업을 수행하게 되고 병렬 처리 지점이 줄어들게 됩니다.
Redshift는 EVEN , KEY 및 ALL을 포함한 여러 배포 스타일을 지원하며, 특정 테이블에 대해 선택된 분산 스타일에 따라 열의 행이 저장될 조각이 결정됩니다.
분석을 수행할 때 가장 일반적인 작업 중 하나는 JOIN 작업입니다.
두 개의 테이블이 있는 예를 살펴보겠습니다. 그 중 하나는 작은 차원 테이블이고 다른 하나는 매우 큰 차원 테이블입니다. 작은 차원 테이블은 단일 노드의 저장소에 쉽게 들어갈 수 있는 반면 큰 테이블은 여러 노드에 분산되어야 합니다.
JOIN 쿼리 와 관련하여 성능에 가장 큰 영향을 미치는 것 중 하나는 노드 간에 데이터를 셔플해야 하는 경우인데, 이를 방지하고 JOIN 성능을 최적화하기 위해 더 작은 차원 테이블을 모든 슬라이스에 저장해야 합니다.
작은 차원 테이블의 경우 ALL 배포 스타일을 지정하여 클러스터합니다 . 큰 테이블의 경우 데이터는 EVEN 배포 스타일을 지정하여 라운드 로빈 방식으로 모든 조각에 균등하게 배포될 수 있습니다 . 이렇게 하면 모든 조각이 작은 차원 테이블의 전체 복사본을 갖게 되며 다른 조각의 차원 데이터를 섞을 필요 없이 큰 팩트 테이블에 대해 보유하고 있는 데이터의 하위 집합과 직접 조인할 수 있습니다.
하지만 이는 쿼리 성능에 이상적일 수 있지만 ALL 분산 스타일에는 클러스터에서 사용하는 스토리지 공간의 양과 관련하여 약간의 오버헤드가 있을 뿐만 아니라 데이터 로드에 대한 부정적인 성능 영향이 있습니다.
따라 이를 대체하여 최적화 할 수 있는 방법은 조인해야 하는 두 테이블의 행을 동일한 슬라이스에 저장하는 것입니다. 이를하는 방법은 KEY 배포 스타일을 사용하는 것입니다. 이는 열 중 하나의 해시 값은 각 테이블의 어떤 행이 어떤 슬라이스에 저장될지 결정하며, 그룹화 및 집계 쿼리의 경우 데이터 셔플링을 줄여 네트워크 I/O를 절약할 수도 있습니다.
이러한 KEY 배포 스타일을 사용하여 동일한 조각에 동일한 키가 있는 레코드를 유지함으로써 달성할 수 있는데,. 이 경우 GROUP BY 절에 사용된 열을 데이터를 배포할 키로 지정합니다. 또한 KEY 배포 에 사용되는 열은 핫 파티션 및 데이터 왜곡을 방지하기 위해 항상 데이터의 카디널리티가 높고 정규 분포가 있는 열이어야 합니다.
이러한 설명은 매우 복잡할 수 있지만 Redshift는 자동으로 배포 스타일과 같은 구성 항목을 최적화 해줍니다.
3.2 Redshift Zone Maps 및 데이터 정렬
쿼리가 결과를 반환하는 데 걸리는 시간은 하드웨어 요소, 특히 디스크 검색 및 디스크 액세스 시간의 양에 영향을 받습니다.
- 디스크 탐색 시간 : 하드 드라이브가 한 블록에서 다른 블록으로 읽기 헤드를 이동하는 데 걸리는 시간
- 디스크 액세스 시간 : 디스크 블록에 저장된 데이터를 읽고 쓰고 요청된 데이터를 다시 클라이언트로 전송하는 대기 시간
데이터 액세스 대기 시간을 줄이기 위해 Redshift는 리더 노드의 각 디스크 블록에 대한 메모리 내 메타데이터를 Zone Maps 에 저장합니다 . 이러한 Zone Maps을 기반으로 Redshift는 쿼리와 관련된 데이터가 포함된 블록을 알고 있으므로 쿼리에 필요한 데이터가 포함되지 않은 읽기 블록을 건너뛸 수 있습니다. 이는 읽기 수를 줄여 쿼리 성능을 최적화하는 데 도움이 됩니다.
Zone Maps 는 블록의 데이터를 정렬할 때 가장 효과적이며, 테이블을 정의할 때 블록 내에서 데이터가 정렬되는 방식을 결정하는 하나 이상의 정렬 키를 선택적으로 정의할 수도 있습니다.
여러 정렬 키를 선택할 때, 복합 정렬 키를 사용하여 키의 우선 순위를 지정하거나 인터리브 정렬 키를 사용하여 각 정렬 키에 동일한 우선 순위를 부여 할 수 있습니다. 기본 정렬 키 유형은 복합 정렬 키이며 대부분의 경우에 권장됩니다.
또한 정렬 키는 범위 필터와 함께 자주 사용되는 열 또는 정기적으로 집계를 계산하는 열에 있어야 하며, Zone Maps의 효율성을 개선하여 쿼리 성능을 크게 높이는 데 도움이 될 수 있지만 수집 작업의 성능을 저하시킬 수도 있습니다.
4. 고성능 데이터 웨어하우스 설계
고성능 데이터 웨어하우스를 설계하려면 여러 요소를 고려해야 합니다. 여기에는 클러스터 유형 및 크기 조정, 압축 유형, 배포 키, 정렬 키, 데이터 유형 및 테이블 제약 조건과 같은 항목이 포함됩니다.
또한 디자인 프로세스의 일부로 비용 대 성능 또는 스토리지 크기 대 성능과 같은 몇 가지 장단점을 고려해야 하며, 인프라 및 스토리지에 대한 결정 외에도 논리적 스키마 설계는 데이터 웨어하우스의 성능을 최적화하는 데에도 큰 역할을 합니다.
4.1 최적의 Redshift 노드 유형 선택
CPU, 메모리, 스토리지 용량 및 스토리지 유형의 조합에 따라 각각 다른 다양한 유형의 노드를 사용할 수 있습니다.
다음은 노드 유형의 세 가지 계열입니다.
- RA3 노드 : 관리형 스토리지와 함께 사용하면 시간당 컴퓨팅 요금과 한 달 동안 사용하는 관리형 스토리지 양에 따라 별도의 요금을 지불하므로 컴퓨팅과 스토리지를 분리할 수 있습니다.스토리지는 로컬 SSD 스토리지와 S3에 저장된 데이터의 조합입니다.
- DC2 노드 : 컴퓨팅 집약적인 워크로드용으로 설계되었으며 노드당 고정된 양의 로컬 SSD 스토리지를 제공합니다. 또한DC2 노드를 사용하면 컴퓨팅과 스토리지가 결합됩니다.
- DS2 노드 : 대용량 하드 디스크 드라이브가 연결된 컴퓨팅을 제공하는 레거시 노드입니다. DS2 노드를 사용하면 컴퓨팅과 스토리지도 결합됩니다.
크기가 1TB 미만의 소규모 데이터 웨어하우스에서는 DC2 노드를 사용하고, 대규모 데이터 웨어하우스는 관리형 스토리지와 함께 RA3 노드를 사용하도록 권장합니다. DS2 노드 유형의 경우, 레거시 노드로 권장하지 않는 유형입니다.
4.2 최적의 테이블 분포 스타일 및 정렬 키 선택
Redshift는 클러스터에서 실행 중인 쿼리를 모니터링하고 최적의 배포 스타일 및 정렬 키를 자동으로 적용할 수 있는 기능이 존재합니다. 이는 쿼리 실행 후 몇 시간 내에 테이블에 최적화가 이뤄집니다.
새 테이블을 생성하고 특정 배포 스타일이나 정렬 키를 지정하지 않으면 Redshift는 두 설정을 모두 AUTO로 설정합니다. 작은 테이블은 초기에 ALL 배포 스타일을 갖도록 설정되지만 큰 테이블은 EVEN 배포 스타일을 갖습니다.
또한 작은 테이블에서 시간에 따라 테이블이 커지면 자동으로 분포 스타일을 EVEN으로 조정하며, 클러스터에서 실행 중인 쿼리를 분석하면서 테이블 배포 스타일을 KEY 기반으로 추가로 조정도 가능합니다.
마찬가지로 Redshift는 실행 중인 쿼리를 분석하여 테이블에 대한 최적의 정렬 키를 결정하며, 테이블 스캔 중에 디스크에서 읽은 데이터 블록을 최적화하는 것을 목표로 최적화가 진행됩니다.
고유한 사용 사례가 필요한 경우 이러한 설정을 수동으로도 구성할 수 있습니다.
4.3 열에 적합한 데이터 유형 선택
Redshift 테이블의 모든 열은 특정 데이터 유형과 연결되며 이 데이터 유형은 열이 특정 제약 조건을 준수하도록 합니다. 이렇게 하면 열의 값에 대해 수행할 수 있는 작업 유형을 적용하는 데 도움이 됩니다.
현재 Amazon Redshift가 지원하는 데이터 유형은 크게 6가지가 있습니다.
4.3.1 문자 유형
문자 데이터 유형은 프로그래밍 언어 및 관계형 데이터베이스의 문자열 데이터 유형과 동일하며 텍스트를 저장하는 데 사용됩니다.
기본 문자 유형으로 다음과 같이 두 가지 문자 유형이 존재합니다.
- CHAR(n) , CHARACTER(n) 및 NCHAR(n) : 단일 바이트 문자만 지원하는 고정 길이 문자열입니다. 데이터는 문자열을 고정 길이로 변환하기 위해 끝에 공백을 두고 저장합니다. 또한 후행 공백이 무시 된다는 특징이 있습니다.
- VARCHAR(n) 및 NVARCHAR(n) : 멀티바이트 문자를 지원하는 가변 길이 문자열입니다. 이 데이터 유형을 생성할 때 지정할 올바른 길이를 결정하려면 문자당 바이트 수에 저장해야 하는 최대 문자 수를 곱해야 하며, 가변 길이 문자열용이므로 후행 공백으로 데이터가 채워지지 않습니다.
문자 유형을 결정할 때 다중 바이트 문자를 저장해야 하는 경우 항상 VARCHAR 데이터 유형을 사용해하며, 데이터가 항상 1바이트 문자로 인코딩되고 항상 고정 길이인 경우 고정 너비 CHAR 데이터 유형을 사용해야 합니다.
불필요하게 긴 길이를 사용하면 복잡한 쿼리의 성능에 영향을 미칠 수 있으므로 가능한 가장 작은 열 크기를 사용하는 것이 좋습니다. 하지만 값이 너무 작으면 삽입하려는 데이터가 지정된 길이보다 크면 쿼리가 실패할 수 있으므로 저장해야 하는 가장 큰 잠재적 값을 고려하고 열을 정의할 때 사용해야합니다.
4.3.2 숫자 유형
Redshift의 숫자 데이터 유형에는 정수, 십진수, 부동 소수점 유형이 존재합니다.
4.3.2.1 정수 유형
정수 유형은 정수를 저장하는 데 사용되며 저장해야 정수의 크기에 따라 다음과 같은 옵션이 존재합니다. 또한 가장 큰 잠재적 값을 저장할 수 있는 가능한 가장 작은 정수 유형을 사용해야만 합니다.
- SMALLINT / INT2 : 이 정수의 범위는 -32,768에서 +32,767입니다.
- INTEGER / INT / INT4 : 이 정수의 범위는 -2147483648에서 +2147483647입니다.
- BIGINT / INT8 : 이 정수의 범위는 – 9223372036854775808에서 +9223372036854775807입니다.
4.3.2.2 십진수 유형
십진수 유형을 사용하면 저장해야 하는 정밀도와 스케일을 지정할 수 있습니다. 정밀도는 소수점 양쪽의 총 자릿수를 나타내고 스케일은 소수점 오른쪽의 자릿수를 나타냅니다.
DECIMAL(precision, scale) 을 지정하여 열을 정의합니다. 열을 생성하고 유형을 DECIMAL(7,3) 로 지정하면 -9999.999에서 +9999.999 범위의 값을 사용할 수 있습니다.
DECIMAL 유형은 결과의 정확성을 제어해야하는 계산의 결과를 저장하는 데 유용합니다.
4.3.2.3 부동 소수점 유형
부동 소수점 유형은 가변 정밀도로 값을 저장하는 데 사용됩니다. 부동 소수점 유형은 엄밀하게 말하면, 정확하지 않은 유형입니다. 즉, 일부 값은 근사값으로 저장되기 때문에 특정 값을 저장하고 다시 읽을 때 약간의 불일치가 나타날 수 있습니다.
Redshift에서 지원되는 두 가지 부동 소수점 유형은 다음과 같습니다.
- REAL / FLOAT4 : 최대 6자리 정밀도 값을 지원합니다.
- DOUBLE PRECISION / FLOAT8 / FLOAT : 최대 15자리 정밀도 값을 지원합니다.
이 데이터 유형은 수학적으로 범위 내에 있지만 문자열 길이가 범위 제한을 초과하는 값에 대한 오버플로 오류를 방지하는 데 사용되며, 해당 유형의 정밀도를 초과하는 값을 삽입하면 값이 잘리게 됩니다. REAL 유형(정밀도 최대 6자리 지원) 열의 경우 7876.7876을 삽입하면 7876.78로 저장됩니다. 또는 787678.7876 값을 삽입하려고 하면 787678로 저장됩니다.
4.3.3 날짜/시간 유형
날짜/시간 유형의 형식은 프로그래밍 언어의 단순 날짜, 시간 또는 타임스탬프 열과 동일합니다.
Redshift에서의 날짜/시간 유형은 다음과 같습니다.
- DATE : 이 열 유형은 연관된 시간 없이 날짜를 저장하는 것을 지원합니다. 또한 데이터는 항상 큰따옴표로 묶어 삽입해야 합니다.
- TIME / TIMEZ : 이 열 유형은 연결된 날짜 없이 시간을 저장하는 것을 지원합니다. TIMEZ는 시간대와 함께 시간을 지정하는 데 사용되며 기본 시간대는 UTC 입니다. 시간은 소수 초에 대해 최대 6자리 정밀도로 저장됩니다.
- TIMESTAMP / TIMESTAMPZ : 이 열 유형은 DATE 와 TIME / TIMEZ 의 조합입니다. 시간 값 없이 날짜를 삽입하거나 부분 시간 값만 이 열 유형에 삽입하는 경우 누락된 값은 모두 00으로 저장됩니다.
4.3.4 부울 유형
부울 유형은 True 또는 False 상태 또는 UNKNOWN 의 싱글바이트 리터럴을 저장하는 데 사용됩니다.
부울 유형 필드에 데이터를 삽입할 때
True 에 대한 유효한 지정자 세트는 {TRUE, 't', 'true', 'y', 'yes', '1'} 입니다.
False 에 대한 유효한 지정자 세트는 {FALSE 'f' 'false' 'n' 'no' '0'} 입니다.
또한 열에 NULL 값이 있으면 UNKNOWN 으로 간주됩니다 .
부울 유형의 열을 삽입하는 데 사용된 리터럴 문자열에 관계없이 데이터는 항상 저장되고 true의 경우 t 로, false의 경우 f 로 표시됩니다 .
4.3.5 HLLSKETCH 유형
HLLSKETCH 유형은 HyperLogLog 알고리즘으로 알려진 결과를 저장하는 복합 데이터 유형입니다 . 이 알고리즘은 큰 다중 집합에서 고유 값의 수를 매우 효율적으로 추정하는 데 사용되며, 시간 경과에 따른 추세를 매핑하는 데 유용합니다
Redshift는 HLLSKETCH 라는 데이터 유형에 HyperLogLog 알고리즘의 결과를 저장합니다.
4.3.6 SUPER 유형
Redshift에서 반구조화된 데이터를 보다 효율적으로 지원하기 위해 SUPER 데이터 유형이 제공됩니다. SUPER 유형은 열에 최대 1MB의 데이터를 로드한 다음 먼저 스키마를 적용할 필요 없이 데이터를 쉽게 쿼리할 수 있습니다. 따라 JSON 문서와 같은 반구조화된 데이터를 쿼리하는데 훨씬 향상된 성능을 만들어 내는데 사용됩니다.
4.4 최적의 테이블 유형 선택
Redshift는 다양한 유형의 테이블을 지원합니다. 사용하기 다양한 목적을 위한 다양한 테이블 유형은 쿼리 성능을 크게 향상시키는 데 도움이 될 수 있습니다.
4.4.1 스토리지와 컴퓨팅 결합 - 로컬 Redshift 테이블
Redshift에서 가장 일반적이고 기본이 되는 테이블 유형은 컴퓨팅 노드의 로컬 디스크에 영구적으로 저장되고 내결함성을 위해 자동으로 복제되는 테이블입니다.
레이크 하우스 아키텍처의 가장 큰 장점 중 하나는 Redshift에서 사용할 수 있는 높은 네트워크 대역폭 및 대용량 고속 캐시와 함께 고성능 로컬 드라이브에 Hot Data 를 배치하여 성능을 향상시키는 것 입니다.
Redshift는 분석에 최적화된 컬럼 데이터 형식으로 데이터를 저장하고 압축 알고리즘을 사용하여 쿼리 실행 시 디스크 조회 시간을 줄입니다. Redshift는 워크로드 관리뿐만 아니라 vacuum, 테이블 정렬, 분포 선택 및 정렬 키와 같은 테이블 유지 관리 작업과 관련된 머신 러닝 기반 자동 최적화를 사용하여 쿼리 성능을 강화할 수 있습니다.
이렇게 컴퓨팅과 스토리지를 결합하면 최고의 성능을 얻을 수 있지만 컴퓨팅이나 스토리지만 확장해야 하는 경우 비용이 불필요하게 증가하게 됩니다.
따라 이 문제를 해결하기 위해 Redshift Managed Storage 가 포함된 RA3 노드가 도입되었습니다. 이 노드는 두 환경의 장점을 모두 제공하며, RA3 노드는 별도로 확장할 수 있는 추가 S3 기반 스토리지뿐만 아니라 고성능 SSD 스토리지와 긴밀하게 결합된 컴퓨팅을 제공합니다. 그렇기에 Redshift는 데이터 액세스 패턴을 기반으로 로컬 스토리지와 S3 관리형 스토리지 간의 데이터 이동을 자동으로 관리하므로 이러한 노드를 사용하기 위해 워크플로를 변경할 필요가 없습니다.
4.4.2 Amazon S3에서 데이터를 쿼리하기 위한 외부 테이블
데이터 레이크를 활용하기 위해 Redshift는 외부 테이블 개념을 지원합니다. 이러한 테이블은 AWS Glue 데이터 카탈로그의 데이터베이스 객체를 가리키는 Redshift의 스키마 객체입니다 .
Glue 데이터 카탈로그의 특정 데이터베이스를 가리키는 Redshift에서 외부 스키마를 생성한 후에는 해당 데이터베이스에 속한 모든 테이블을 쿼리할 수 있으며 Redshift Spectrum은 기본 Amazon S3 파일에서 데이터에 액세스합니다 . Redshift Spectrum은 Amazon S3에서 대규모 데이터 세트를 읽을 때 인상적인 성능을 제공하지만 일반적으로 동일한 데이터 세트가 Redshift 컴퓨팅 노드의 로컬 디스크에 저장된 경우 읽는 것만큼 빠르지 않습니다.
그렇지만 S3 데이터 레이크에서 직접 데이터에 액세스함으로써 데이터 웨어하우스 클러스터 전체에서 데이터의 여러 복사본을 복제하는 것을 방지합니다. 따라 Redshift Spectrum을 사용하면 지속적으로 데이터 레이크 데이터 세트를 Redshift로 로드하고 새로 고칠 필요 없이 데이터 레이크 데이터의 단일 소스에 직접 액세스하면서 여전히 인상적인 성능을 얻을 수 있습니다.
4.4.3 Redshift로 데이터를 로드하기 위한 임시 스테이징 테이블
Redshift는 다른 많은 데이터 웨어하우징 시스템과 마찬가지로 임시 테이블 개념을 지원합니다. 임시 테이블의 경우 세션마다 모두 다르며 세션 종료 시 자동으로 삭제되어 복구할 수 없습니다.
그러나 임시 테이블은 임시 테이블은 영구 테이블과 같은 방식으로 복제되지 않고 임시 테이블에 데이터를 삽입해도 자동 클러스터 증분 백업 작업이 트리거되지 않으므로 일부 작업의 성능이 향상됩니다. 임시 테이블의 일반적인 용도 중 하나는 데이터를 업데이트하고 기존 테이블에 삽입하는 것입니다.
기존의 트랜잭션 데이터베이스는 CDC (변경 데이터 캡처) 에 유용한 UPSERT 라는 작업을 지원합니다 . UPSERT 트랜잭션은 새 데이터를 읽고 기본 키를 기반으로 일치하는 기존 레코드가 있는지 확인합니다. 기존 레코드가 있으면 새 데이터로 레코드를 업데이트하고, 기존 레코드가 없으면 새 레코드를 생성합니다.
Redshift는 기본 키 개념을 지원하지만 이는 정보 제공용이며 쿼리 최적화 프로그램에서만 사용됩니다. Redshift는 고유한 기본 키 또는 외래 키 제약 조건을 적용하지 않습니다. 따라 UPSERT 은 Redshift에서 기본적으로 지원되지 않는 것을 유의해야 합니다.
4.4.4 Redshift 구체화된 보기를 사용한 데이터 캐싱
데이터 웨어하우스는 종종 비즈니스 인텔리전스 솔루션의 백엔드 쿼리 엔진으로 사용됩니다. Amazon QuickSight로 데이터 시각화와 같은 시각화 도구를 사용하여 Amazon Redshift에 저장된 데이터를 기반으로 대시보드를 구축할 수 있습니다.
다양한 비즈니스 사용자가 대시보드에 액세스하여 다양한 데이터 세트를 시각화, 필터링 및 드릴다운 합니다. 종종 특정 시각화를 생성하는 데 필요한 쿼리는 여러 Redshift 테이블의 데이터를 참조하고 JOIN해야 하며 잠재적으로 데이터에 대한 집계 및 기타 계산을 수행해야 합니다.
동일한 쿼리를 다시 실행하고 다른 사용자가 대시보드에 액세스할 때 구체화된 VIEW 라는 것을 생성하여 쿼리 결과를 효과적으로 캐시할 수 있습니다 .
구체화된 VIEW는 JOIN 결과, 산술 계산 및 집계와 같은 비용이 많이 드는 작업을 미리 계산한 다음 쿼리 결과를 VIEW 에 저장하여 쿼리 성능을 몇 배로 향상시킵니다. 그러면 테이블을 직접 쿼리하지 않고 뷰를 쿼리하도록 BI 도구를 구성할 수 있습니다. BI 도구의 관점에서 구체화된 VIEW 에 액세스하는 것은 테이블에 액세스하는 것과 동일합니다.
그러나 기본 데이터 테이블이 업데이트될 때 구체화된 VIEW 는 업데이트되지 않으며 기본 테이블의 전체 로드 또는 증분 로드 후에 보기를 새로 고치려면 구체화된 VIEW 를 새롭게 업데이트하는 Redshift SQL 문을 실행해야 합니다.
5. 데이터 레이크와 Redshift 간에 데이터 이동
데이터 레이크와 데이터 웨어하우스 간에 데이터를 이동하는 것은 굉장히 일반적으로 요구됩니다. 따라 데이터 레이크에서 데이터를 수집하고 데이터 레이크로 데이터를 다시 내보내기 위한 방법에 대해서 보겠습니다.
5.1 Redshift 에서 데이터 수집 최적화
Redshift에 데이터를 삽입할 수 있는 다양한 방법이 있지만 권장되는 방법은 Redshift COPY 명령을 사용하여 데이터를 대량 수집하는 것입니다. COPY 명령을 사용하면 다음 소스에서 최적화된 데이터를 수집할 수 있습니다 .
- AWS S3
- AWS DynamoDB
- Amazon Elastic Map Reduce(EMR)
- 원격 SSH 호스트
COPY 명령을 실행할 때 소스를 읽을 수 있는 관련 권한과 필수 Redshift 권한이 있는 IAM 역할 또는 IAM 사용자의 액세스 키 및 보안 액세스 키를 지정해야 하며, COPY 명령 으로 IAM 역할을 생성하고 사용할 것을 권장합니다 .
Amazon S3, Amazon EMR 또는 SSH를 통해 원격 호스트에서 데이터를 읽을 때 COPY 명령은 CSV, Parquet, Avro, JSON, ORC 등을 비롯한 다양한 형식을 지원합니다.
파일을 Redshift로 수집할 때 클러스터의 여러 컴퓨팅 노드를 활용하려면 수집 파일 수를 클러스터의 슬라이스 수와 일치시키는 것을 목표로 해야합니다. 클러스터의 각 조각은 클러스터의 다른 모든 조각과 병렬로 데이터를 수집할 수 있으므로 다음 다이어그램과 같이 파일 수를 조각 수와 일치시키면 수집 작업에 대한 최대 성능을 얻을 수 있습니다.
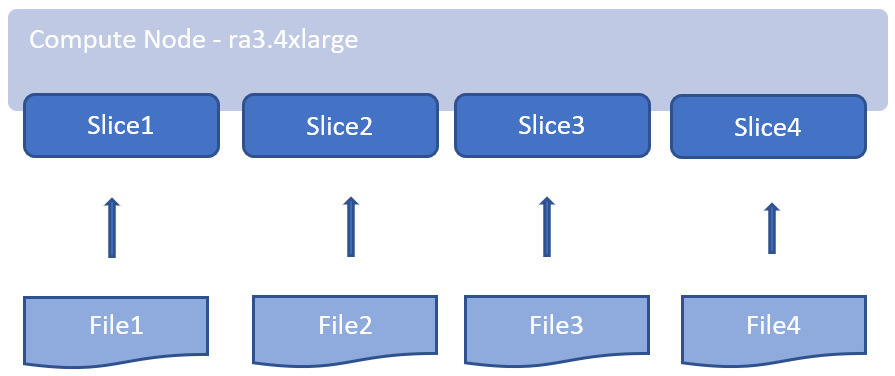
하나의 큰 파일이 있는 경우 각 파일의 크기가 1MB에서 1GB(압축 후)인 여러 파일로 분할하는 것이 필요합니다.
COPY 명령을 사용하여 데이터를 수집 할 때 COPY 작업은 모든 파일에서 단일 트랜잭션으로 처리됩니다. 64개 파일 중 하나라도 복사에 실패하면 전체 복사가 중단되고 트랜잭션이 롤백됩니다.
INSERT 문을 사용하여 테이블에 행을 추가하거나 단일 행 또는 몇 개의 행만 추가할 수 있지만 INSERT 문을 사용하는 것은 권장되지 않으며, INSERT 문을 사용하여 테이블에 데이터를 추가하는 것은 COPY 명령을 사용하여 데이터를 수집하는 것보다 훨씬 느립니다.
INSERT 문을 사용하여 데이터를 추가해야 하는 경우 쉼표로 구분된 여러 행을 지정하여 다중 행 삽입을 사용하여 단일 문으로 여러 행을 삽입할 수 있으나, 성능을 개선하고 데이터 블록이 저장되는 방식을 최대화하려면 단일 INSERT 문으로 가능한 한 많은 행을 추가해야 합니다.
5.2 Redshift에서 데이터 레이크로 데이터 내보내기
COPY 명령을 사용하여 데이터를 Redshift로 수집하는 방법과 유사하게 UNLOAD 명령을 사용하여 Redshift 클러스터에서 Amazon S3로 데이터를 복사할 수 있습니다.
UNLOAD 의 성능을 최대화하기 위해 Redshift는 클러스터의 여러 슬라이스를 사용하여 데이터를 여러 파일에 씁니다. 이후, SELECT 쿼리를 지정하여 언로드할 데이터를 결정합니다. 이때 전체 단일 테이블을 언로드하려면 UNLOAD 문 에 SELECT * from TABLENAME을 지정해야 합니다.
UNLOAD 문에서 여러 테이블을 조인하는 쿼리 또는WHERE 절을 사용하여 테이블의 데이터 하위 집합만 언로드하는 쿼리와 같은 고급 쿼리를 사용할 수 도 있는데, 데이터를 다시 Redshift로 로드하려는 경우에는 쿼리에 ORDER BY 절을 지정하는 것이 좋습니다.
기본적으로 데이터는 파이프로 구분된 텍스트 형식으로 언로드되지만 Parquet에서 데이터 언로드형식도 지원합니다. 대부분의 경우 데이터를 데이터 레이크로 내보내는 경우 언로드된 데이터에 대해 Parquet 형식을 지정하는 것이 좋습니다. Parquet 형식은 분석에 최적화되고 압축되며 Parquet 형식으로 언로드할 때 텍스트 형식으로 언로드할 때보다 언로드 성능이 최대 2배 빠를 수 있습니다.
특정 데이터 세트에서 정기적으로 UNLOAD를 수행하는 경우 ALLOWOVERWRITE 옵션을 사용하여 Redshift가 지정된 경로의 기존 파일을 덮어쓰도록 할 수 있으며, CLEANPATH 옵션을 사용하여 데이터를 쓰기 전에 지정된 경로에서 기존 파일을 제거할 수도 있습니다.
대용량 데이터 세트를 데이터 레이크로 언로드하기 위한 또 다른 권장 사항은 PARTITION 옵션 을 지정 하고 데이터를 분할해야 하는 하나 이상의 열을 제공하는 것이며, CLEANPATH 옵션과 함께 PARTITION 옵션을 사용하는 경우에는 작성하는 특정 파티션에 대한 파일만 삭제합니다.