[AWS Data Engineering] 5장 데이터 엔지니어링 파이프라인 설계
<Data Engineering with AWS>의 5장 내용을 번역 및 요약 정리한 내용입니다.
https://www.amazon.com/Data-Engineering-AWS-Gareth-Eagar/dp/1800560419
Data Engineering with AWS: Learn how to design and build cloud-based data transformation pipelines using AWS: 9781800560413: Com
Gareth has worked in the IT industry for over 25 years, starting in South Africa, working in the United Kingdom for a few years, and is now based in the United States. In 2017, Gareth started working at Amazon Web Services (AWS) as a Solution Architect, wo
www.amazon.com
데이터 파이프라인은 여러 소스에서 데이터를 수집하고 데이터를 최적화 및 변환하며 데이터 사용자가 잘 사용할 수 있도록 하는 프로세스입니다. 여기서 데이터 엔지니어의 중요한 역할은 이러한 파이프라인을 설계하는 능력입니다. 따라 이번에 진행되는 주제는 다음과 같습니다.
1.데이터 파이프라인 아키텍처
2.데이터 소비자 식별 및 요구 사항 이해
3.데이터 소스 식별 및 데이터 수집
4.데이터 변환 및 최적화 식별
5.데이터 마트에 데이터 로드
6.화이트보드 세션 마무리
1. 데이터 파이프라인 아키텍처
아키텍처에 들어갈 개별 구성 요소의 세부 정보를 살펴보기 전에 하려는 작업을 거시적으로 보는 것 역시 도움이 됩니다.
새로운 데이터 엔지니어링 프로젝트를 시작할 때 흔히 저지르는 실수는 한번에 모든 아키텍처를 구성할려고 하는 것입니다. 이를 방지하기 위해서는 한번에 구체적인 아키텍처를 완성하기보다는 큰 그림을 그린 후, 이후에 하나씩 구체적인 사항을 추가해 나가야 합니다.
1.1 데이터 파이프라인 설계
거시적인 데이터 파이프라인을 설계하기 위해서는 다음과 같은 과정이 요구됩니다.
- 프로젝트 스폰서 및 데이터 소비자로부터 요구 사항 파악(목표가 무엇인지, 데이터 사용 도구는 무엇인지, 필요한 데이터 변환이 무엇인지 등)
- 사용 가능한 데이터 소스에 대한 정보 수집(원시 데이터를 저장하는 시스템, 데이터 형식, 시스템 및 데이터 소유자 등)
- 사용 가능한 도구 유형과 이러한 요구 사항에 가장 적합한 도구 유형을 결정
이때 이러한 정보를 수집하는 유용한 방법 중 하나는 화이트보드 세션을 진행하는 것입니다.
1.2 정보 수집 도구로서의 화이트보드
화이트보드 세션을 진행하면 데이터 엔지니어는 데이터 파이프라인에 대한 계획을 세우고 시작하는 데 필요한 정보를 수집할 수 있습니다.
화이트보드의 목적은 모든 기술적 세부 사항을 해결하고 사용할 특정 서비스 및 도구를 완벽하게 정리하는 것이 아닙니다. 오히려 파이프라인에 대한 전반적인 접근 방식에 대해 이해 관계자와 합의하고 세부 설계에 필요한 정보를 수집하는 것에 가깝습니다.
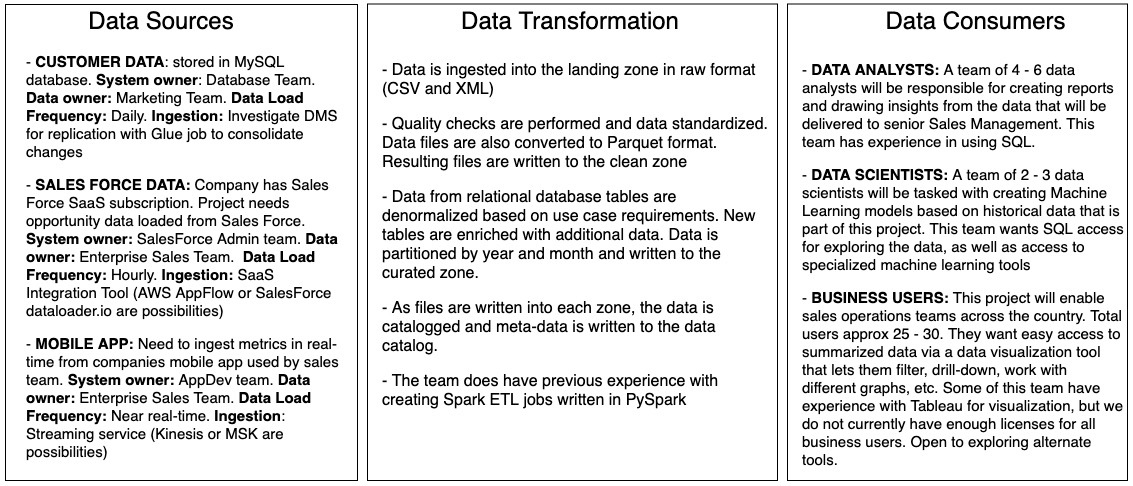
다음은 일반적인 데이터 파이프라인의 기본 구성 요소에 대한 개요와 파이프라인 아키텍처를 개발하는 접근 방식을 보여줍니다.
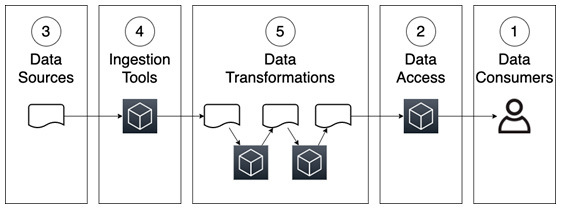
파이프라인 설계에 접근할 때 다음과 같은 순서를 사용할 수 있습니다
- 비즈니스 목표, 데이터 소비자 및 요구 사항 이해
- 데이터 소비자가 데이터에 액세스하는 데 사용할 도구 유형 결정
- 어떤 잠재적인 데이터 소스를 사용할 수 있는지 이해
- 데이터 수집에 사용할 도구 세트 유형 결정
- 원시 데이터를 가져와 데이터 소비자를 위해 준비하기 위해 높은 수준에서 필요한 데이터 변환 이해
파이프라인을 설계할 때는 항상 거꾸로 작업해야 합니다. 즉, 데이터 소비자와 그들의 요구 사항으로 시작한 다음 거기에서 작업하여 파이프라인을 설계해야 합니다.
1.3 화이트보드 세션 진행
프로젝트 초기에 데이터 엔지니어는 이와 관련된 이해관계자들과 워크숍을 진행해야 합니다. 이때 아래와 같은 질문들을 통해서 그들의 요구를 파악해야 합니다.
- 해당 프로젝트를 지원해주는 경영진은 누구이며, 프로젝트의 비즈니스 가치와 목표는 무엇인가요?
- 데이터를 통해 직접 작업할 사람(데이터 소비자)은 누구인가요?
- 데이터 소비자가 데이터에 접근하기 위해 어떤 도구를 사용할 것 인가요?
- 해당 프로젝트의 원시 데이터 소스는 무엇인가요?
- 원시 데이터를 변환하고 최적화하기 위해서는 어떤 형태의 변환이 요구되나요?
이때 중요한 점은 해당 질문 등을 통해서 비지니스의 목표를 이해하는 것입니다. 이러한 과정을 통해, 팀이 비즈니스의 목표를 이해하게 된다면 화이트보드를 통해 높은 수준의 파이프라인을 구성할 수 있게됩니다.
2. 데이터 소비자 식별 및 요구 사항 이해
일반적인 조직에는 아래와 같은 다양한 범주 또는 유형의 데이터 소비자가 있습니다.
- 비즈니스 사용자 : 비즈니스 사용자는 일반적으로 대화형 혹은 시각화된 대시보드를 통해 데이터에 액세스하기를 원합니다.
- 비즈니스 애플리케이션 : 일부 사례에서 데이터 엔지니어가 구축하는 데이터 파이프라인은 다른 비즈니스 애플리케이션을 지원하는 데 사용됩니다.
- 데이터 분석가 : 데이터 분석가는 더 복잡한 데이터 분석을 수행하고 특정 질문에 답하기 위해 대규모 데이터 세트를 더 깊이 파고드는 임무를 맡는 경우가 많습니다. 이러한 사용자는 일반적으로 SQL과 같은 구조화된 쿼리 언어를 사용합니다.
- 데이터 과학자 : 데이터 과학자는 머신러닝 모델을 생성하는 임무를 맡습니다. 대규모 데이터 세트에서 명확하지 않은 패턴을 식별하거나 과거 데이터를 기반으로 미래 행동에 대한 예측을 합니다. 이를 위해 데이터 과학자는 더 세분화할 수 있는 대량의 다양한 데이터 세트에 액세스해야 합니다.
화이트보드 워크샵 중에 데이터 엔지니어는 식별된 프로젝트의 데이터 소비자가 누구인지 이해하기 위해 질문을 해야 합니다. 또한 그들이 사용하는 도구를 이해하는 것 역시 중요합니다.
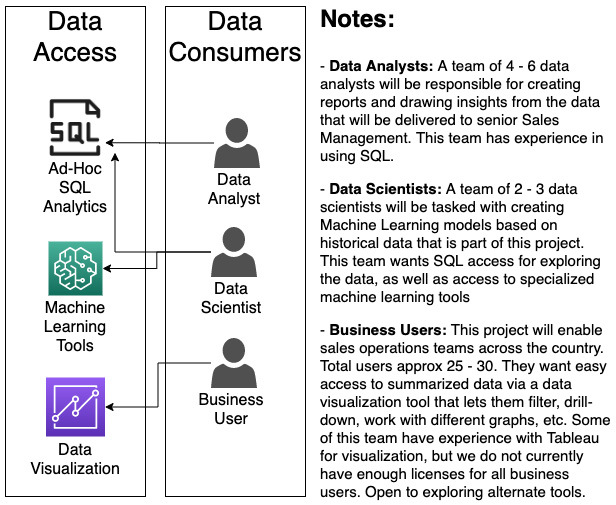
프로젝트의 데이터 소비자가 누구인지, 데이터 작업에 사용하려는 도구를 잘 이해하면 "데이터 소스 식별 및 데이터 수집" 단계로 넘어갈 수 있게 됩니다.
3. 데이터 소스 식별 및 데이터 수집
대부분의 데이터 소스는 조직 내부에 있으나, 일부 프로젝트에서는 다른 타사 데이터 소스를 통해 데이터를 보강해야 할 수도 있습니다. 따라 데이터 소스를 논의할 때 내부 및 외부 데이터 세트를 모두 고려해야 합니다.
워크샵에서 데이터 엔지니어는 아래와 같은 질문들을 통해 이를 파악하는 것이 중요합니다.
- 데이터가 포함된 소스 시스템에 대한 세부 정보 (데이터베이스의 데이터, 서버의 파일, Amazon S3의 기존 파일, 스트리밍 소스에서 오는 데이터 등)
- 이 데이터가 내부 데이터라면 비즈니스 내 소스 시스템의 소유자는 누구인가요? 데이터의 소유자는 누구인가요?
- 데이터를 수집해야 하는 빈도는 어떻게 되나요? (지속적인 스트리밍/복제, 몇 시간마다 데이터 로드, 하루에 한 번 데이터 로드)
- 선택적 데이터 수집에 사용할 수 있는 도구에 대해 논의
- 데이터의 원시/수집 형식은 무엇인가요? (CSV, JSON, 기본 데이터베이스 형식 등)
- 데이터 원본에 PII 또는 거버넌스 제어가 필요한 유형의 데이터가 포함되어 있나요? 그렇다면 데이터를 보호하기 위해 어떤 통제가 필요한가요?
정보가 검색되면 다음과 같이 화이트보드에 정리할 수 있게 됩니다.
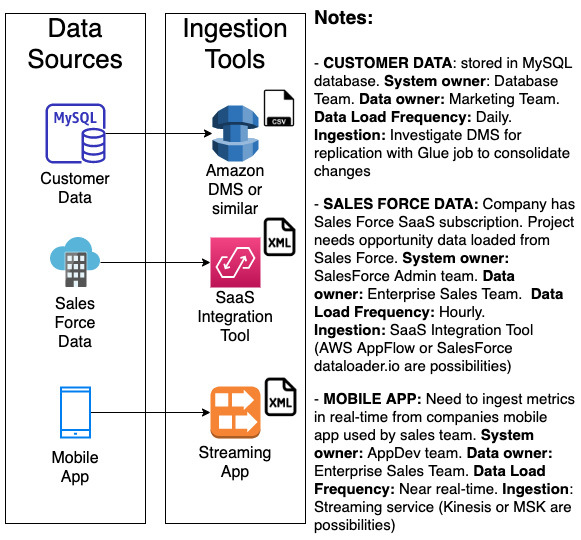
화이트보드 프로세스 중에 요구 사항에 대한 추가 컨텍스트 또는 세부 정보를 제공하기 위해 추가적인 메모 역시 필요합니다. 이는 화이트보드에서 직접 캡처하거나 별도로 캡처할 수 있습니다.
이 예에서 우리는 MySQL 데이터베이스의 고객 데이터, Salesforce의 기회 정보, 조직의 모바일 애플리케이션에서 얻은 거의 실시간 판매 지표 등 세 가지 데이터 소스를 확인했습니다. 우리는 또한 다음을 확인했습니다.
- 각 소스 시스템을 소유한 사업팀과 데이터를 소유한 사업팀
- 데이터 수집 속도(각 데이터 소스를 수집해야 하는 빈도)
- 데이터 수집에 사용할 수 있는 잠재적 서비스
수집 도구에 대해 논의할 때 어떤 도구가 적합할지 잘 알고 있다면 잠재적인 도구를 캡처하는 것이 좋습니다. 그러나 이 세션으로 모든 기술 구성 요소에 대한 최종 아키텍처 및 결정을 제시하는 것이 아닙니다. 추가 세션은 잠재적인 도구 집합을 요구 사항에 대해 철저히 평가하는 데 사용되며 소스 시스템 소유자와 긴밀한 협의를 거쳐야 합니다.
이 화이트보드 세션 동안 우리는 거꾸로 작업하면서 먼저 데이터 소비자를 식별한 다음 사용할 데이터 소스를 식별했습니다. 이 시점에서 우리는 "분석을 위해 데이터를 최적화하기 위해 사용할 계획인 일부 데이터 변환을 검토"하는 단계로 이동할 수 있습니다.
4. 데이터 변환 및 최적화 식별
일반적인 데이터 분석 프로젝트에서는 여러 데이터 소스에서 데이터를 수집한 다음 해당 데이터 세트에서 변환을 수행하여 필요한 분석에 맞게 최적화합니다.
4.1 파일 형식 최적화
CSV, XML, JSON 및 기타 유형의 일반 텍스트 파일은 일반적으로 정형 및 반정형 데이터를 저장하는 데 사용됩니다. 이러한 파일 형식은 수동으로 데이터를 탐색할 때 유용하지만 훨씬 더 나은 이진 파일 형식을 사용할 수 있습니다.컴퓨터 기반 분석에 최적화된 일반적인 이진 형식은 Apache Parquet 형식입니다. 일반적인 변환은 일반 텍스트 파일을 Apache Parquet와 같은 최적화된 형식으로 변환하는 것입니다.
4.2 데이터 표준화
파이프라인을 구축할 때 서로 다른 여러 데이터 소스에서 데이터를 로드하는 경우가 많습니다. 이러한 각 데이터 소스는동일한 항목을 참조하기 위해 서로 다른 명명 규칙을 가질 수 있습니다. 분석을 위해 데이터를 최적화할 때 할 수 있는 작업 중 하나는 열 이름, 유형 및 형식을 표준화하는 것입니다. 전사적 분석 프로그램을 통해 표준을 만들고 채택할 수 있습니다.
4.3 데이터 품질 확인
데이터 변환의 또 다른 측면은 데이터의 예상 품질 표준을 충족하지 않는 데이터를 찾아내는 것입니다.
4.4 데이터 분할
분석을 위한 일반적인 최적화 전략은 쿼리에서 자주 사용되는 필드별로 물리적 스토리지 계층의 데이터를 그룹화하여 데이터를 분할하는 것입니다.
4.5 데이터 비정규화
기존의 관계형 데이터베이스 시스템에서는 데이터가 정규화됩니다. 즉, 각 테이블에는 특정 주제에 대한 정보가 포함되고 관련 정보는 별도의 테이블에 포함된다는 의미입니다. 따라 외래 키를 사용하여 테이블을 연결해야 합니다.
데이터 레이크의 경우에는 여러 테이블의 데이터를 단일 테이블로 결합하면 종종 쿼리 성능이 향상될 수 있습니다. 따라 두 개(또는 그 이상)의 테이블을 사용하여 두 테이블의 데이터로 새 테이블을 만드는 데이터 비정규화를 진행합니다..
4.6 데이터 카탈로그
파이프라인의 변환 섹션에 포함해야 하는 또 다른 중요한 구성 요소 아키텍처는 데이터 세트를 분류하는 프로세스입니다. 이 프로세스를 통해, 데이터 레이크의 모든 데이터 세트가 데이터 카탈로그에서 참조되고 추가 비즈니스 메타데이터를 추가할 수 있는지 확인합니다.
4.7 화이트보드 데이터 변환
화이트보드 세션의 경우 필요한 변환의 모든 세부 정보를 결정할 필요는 없지만 높은 수준의 파이프라인 설계를 위한 데이터 변환에 유용합니다.
데이터 엔지니어가 화이트보드 세션 중에 데이터 변환에 대해 정보를 수집해야 합니다. 이때 아래와 같은 질문들을 통해서 그들의 요구를 파악할 수 있습니다.
- 참조할 수 있는 기존의 표준화된 열 이름 정의 및 형식 집합이 있나요? 그렇지 않다면 누가 이러한 전사적 분석 프로그램을 통해 표준 정의를 생성할 수 있나요?
- 데이터 세트에 대해 어떤 추가 비즈니스 메타데이터를 캡처해야 하나요?
- 최적화된 파일은 어떤 형식으로 저장해야 하나요?
- 데이터를 분할해야 하는 명확한 필드가 있나요?
- 현재 다른 필수 데이터 변환이 반드시 필요한가요?
- 팀에는 어떤 데이터 변환 엔진/기술을 사용하나요?
정보가 검색되면 다음 다이어그램과 같이 화이트보드에 캡처할 수 있습니다.
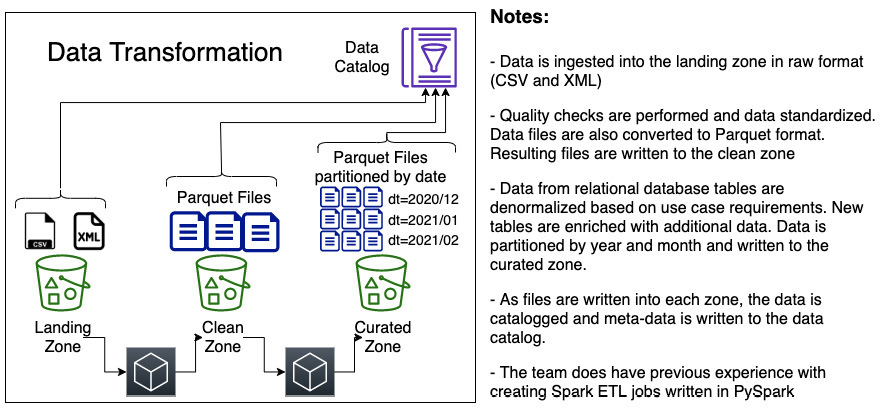
이 예에서는 3개의 영역이 존재합니다. (랜딩 영역, 클린 영역 및 선별된 영역)
1. 원시 파일은 랜딩 존으로 수집되며 CSV 및 XML과 같은 일반 텍스트 형식입니다. 파일이 수집되면 파일에 대한 정보가 추가 비즈니스 메타데이터(데이터 소유자, 데이터 민감도 등)와 함께 데이터 카탈로그에 캡처됩니다.
2. 현재로서는 특정 데이터 변환 엔진을 식별하지 못했지만 팀이 이전에 PySpark를 사용하여 Spark ETL 작업을 생성한 경험이 있음을 나타내는 메모를 캡처했습니다.
3. 파이프라인의 일부로 랜딩 존의 데이터에 대한 데이터 품질 검사를 실행하는 프로세스가 있습니다. 품질 검사를 통과하면 데이터를 표준화하고 파일을 Apache Parquet 형식으로 변환하여 클린 영역에 새 파일을 작성합니다. 다시 한 번 관련 비즈니스 메타데이터를 포함하여 새로 작성된 파일을 데이터 카탈로그에 추가합니다.
4. 파이프라인의 다른 부분은 이제 특정 사용 사례 요구 사항에 따라 데이터에 대한 추가 변환을 수행합니다. 예를 들어 관계형 데이터베이스의 데이터비정규화되고 추가 데이터로 테이블을 보강할 수 있습니다. 변환된 데이터를 큐레이팅된 영역에 기록하고 기록된 날짜별로 파일을 분할합니다. 다시 한 번 관련 비즈니스 메타데이터를 포함하여 새로 작성된 파일을 데이터 카탈로그에 추가합니다.
여기서의 목표는 모든 기술적 세부 사항을 해결하는 것이 아니라 파이프라인에 대한 높은 수준의 개요를 만드는 것임을 기억하는 것이 중요합니다. 이렇게 데이터 변환을 결정했으면 "데이터 마트가 필요한지 여부를 결정"하는 화이트보드 프로세스의 마지막 단계로 이동합니다.
5. 데이터 마트에 데이터 로드
AWS 데이터 엔지니어 도구 키트에서 다룬 것처럼 많은 도구가 데이터 레이크의 데이터로 직접 작업할 수 있습니다.
이러한 도구는 Amazon S3에서 직접 데이터를 읽지만, 사용 사례에 훨씬 더 짧은 지연 시간과 더 높은 성능의 데이터 읽기가 필요한 경우가 있습니다. 또한 고도로 구조화된 스키마를 사용하는 것이 사용 사례의 분석 요구 사항을 가장 잘 충족하는 경우가 있을 수도 있습니다. 따라 이러한 경우에는 데이터 레이크에서 데이터 마트로 데이터를 로드하는 것이 좋습니다.
분석 환경에서 데이터 마트는 대부분 데이터 웨어하우스 시스템이지만 사용 사례의 요구 사항에 따라 관계형 데이터베이스 시스템일 수도 있습니다. 그렇지만 두 경우 모두 로컬 저장소와 로컬 컴퓨팅 성능을 갖추고 있어 대규모 데이터 세트에서 쿼리해야 할 때, 특히 쿼리가 여러 테이블에서 조인해야 하는 경우에 최고의 성능을 제공합니다.
그렇기에 화이트보드 세션의 일부로 데이터 마트가 데이터의 하위 집합을 로드하는 데 가장 적합한지 논의하는 것이 필요합니다.
6. 화이트보드 세션 마무리
화이트보드 세션을 완료하게 되면, 빌드하려는 파이프라인의 주요 구성 요소를 설명하는 높은 수준의 개요 아키텍처가 존재합니다. 하지만 이 시점에서 여전히 답변되지 않은 질문들이 많을 것이며, 구체적인 세부 사항 역시 정해지지 않았을 것입니다. 하지만 이렇게 구성된 아키텍처는 이해 관계자들이 보기에도 한 눈에 파악되어야 하며, 필요에 따라 후속 세션을 준비하여야 하기도 합니다.
세션 후에 알아야 할 정보 중 일부는 다음과 같습니다.
- 이 프로젝트의 데이터 소비자가 누구인지 잘 이해하는 것
- 데이터 소비자의 각 범주에 대해 데이터에 액세스하는 데 사용할 도구 유형에 대한 좋은 아이디어는 무엇이 있는지
- 사용될 내부 및 외부 데이터 소스에 대한 이해
- 각 데이터에 대해 소스, 데이터 수집 빈도에 대한 요구 사항 이해
- 각 데이터 소스에 대해 데이터를 소유한 사람과 데이터를 포함하는 소스 시스템을 소유한 사람의 목록
- 가능한 데이터 변환에 대한 높은 수준의 이해
- 데이터 웨어하우스 또는 기타 데이터 마트에 데이터 하위 집합을 로드해야 하는지 여부에 대한 이해
세션이 끝나면 최종 종합된 아키텍처를 작성하고 세션에서 얻은 정보들을 작성해서 정리한 메모 역시 필요합니다. 이 메모는 프로젝트를 진행하는 것에 대한 승인 및 동의를 요청하기 위해 모든 참가자에게 배포되어야 합니다.
이러한 과정 이후, 승인 및 동의를 받게 되면 구체적인 정보를 추가로 요청하고 이를 검토하기 위해 다른 팀과 추가적인 세션이 필요하게 됩니다.
따라 이번의 단계를 모두 거쳐서 나오게 되는 아키텍처의 구성은 다음과 같습니다
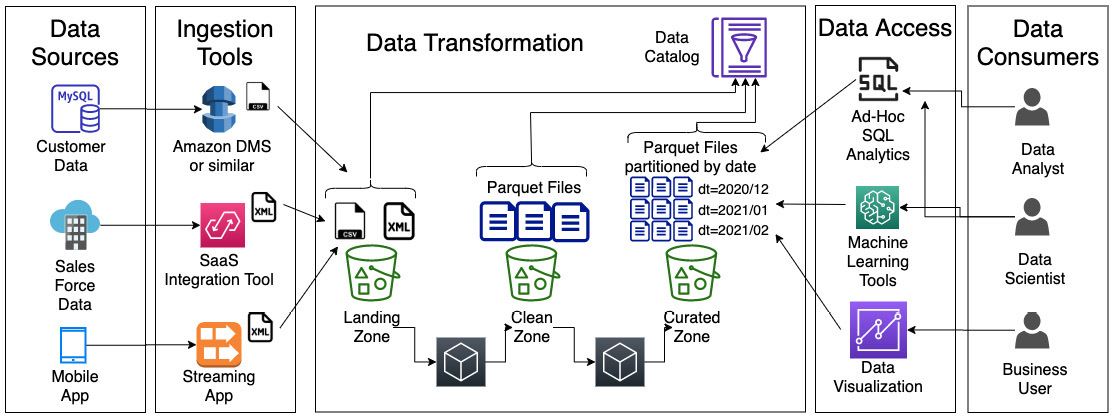
세션에서 얻은 정보들을 작성해서 정리한 메모는 다음과 같습니다.