[머신러닝/딥러닝]경진대회_범주형 데이터 이진분류(2)
<머신러닝. 딥러닝 문제해결 전략> 2부 7장 실습하고 해당 내용을 정리한 내용입니다.
https://www.kaggle.com/competitions/cat-in-the-dat
Categorical Feature Encoding Challenge | Kaggle
www.kaggle.com
1. 베이스라인 모델
베이스라인 모델에서는 모든 피처를 원-핫 인코딩한 뒤, 로지스틱 회귀 모델로 베이스라인을 만들겠습니다.
전체적인 순서는 아래의 표와 같습니다. 다음 '성능 개선 Ⅰ'에서 밑줄친 부분을 통해 더욱 성능을 개선할 방향이니 어떻게 개선하면 좋을지 생각하면서 읽는 것도 하나의 좋은 방법입니다.
| 데이터 불러오기 | |
| (기본적인) 피처 엔지니어링 | 모든 피처 원-핫 인코딩 |
| 평가지표 계산 함수 작성 | ROC AUC(사이킷런 제공) |
| 모델 훈련 | 모델 : 로지스틱 회귀 (사이킷런 제공) |
| 성능 검증 | |
| 제출 | |
먼저 훈련, 테스트, 제출 샘플 파일을 불러옵니다.
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/cat-in-the-dat/'
train = pd.read_csv(data_path + 'train.csv', index_col='id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')01. 피처 엔지니어링
- 데이터 합치기
머신러닝 모델은 문자 데이터를 인식하지 못합니다. 따라서 문자를 숫자로 바꿔주는 작업이 필요합니다.
이처럼 데이터의 표현 형태를 바꾸는 작업을 인코딩이라고 합니다.
불러온 데이터는 문자를 포함한 데이터 이므로 인코딩을 해야합니다. 훈련 데이터와 테스트 데이터에 동일한 인코딩을 적용하기 위해 둘을 합친 후에, 인코딩 작업을 진행하겠습니다. 이후 합친 DataFrame 에서 타깃값을 제거하겠습니다. 왜냐하면 피처와 타깃값은 따로 분리해서 모델링이 필요하기 때문입니다.
all_data = pd.concat([train, test]) # 훈련 데이터와 테스트 데이터 합치기
all_data = all_data.drop('target',axis=1)
all_dataconcat() 함수를 사용하여 축을 따라 두 DataFrame을 합친후, 합친 데이터인 all_data에서 drop() 함수를 통해 타깃값을 제거했습니다. 결과는 다음과 같습니다.

훈련 데이터와 테스트 데이터를 합치니 행 개수가 50만 개이며, 타깃값이 빠져서 피처는 23개 입니다.
- 원-핫 인코딩
원-핫 인코딩은 대표적인 인코딩 방법입니다. 모델링에 사용하기 위해 모든 피처를 원-핫 인코딩 해보겠습니다.
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder() # 원-핫 인코더 생성 ⓐ
all_data_encoded = encoder.fit_transform(all_data) # 원-핫 인코더 적용 ⓑⓐ 원-핫 인코더 객체를 생성하고 ⓑ all_data의 모든 피처를 인코딩하여 새로운 변수 all_data_encoded에 저장했습니다. 한 번의 작업으로 간단하게 인코딩이 끝났습니다!
| ※ all_data에는 문자로 구성된 피처와 숫자로 구성된 피처가 섞여 있습니다. 문자로 구성된 피처는 반드시 인코딩이 필요합니다. 하지만 숫자로 구성된 피처는 반드시 인코딩할 필요는 없습니다. 단, 모델 성능을 더 좋게 하기 위해 숫자로 구성된 범주형 피처도 인코딩하는 경우가 있습니다. 여기서는 편의상 모든 피처를 인코딩하였으나, '성능 개선 Ⅰ'에서는 피처 특성에 따라 다른 인코딩은 적용합니다. |
- 데이터 나누기
공통으로 적용할 인코딩이 끝났으니 다시 훈련 데이터와 테스트 데이터를 다시 나누겠습니다. 앞서 concat() 함수를 사용해 훈련 데이터와 테스트 데이터를 붙였습니다. 이는 행 번호를 기준으로 다시 나눌 수 있단 의미가 됩니다!
num_train = len(train) # 훈련 데이터 개수
# 훈련 데이터와 테스트 데이터 나누기
X_train = all_data_encoded[:num_train] # 0~num_train - 1행
X_test = all_data_encoded[num_train:] # num_train~마지막 행
y = train['target']추가로 마지막 줄에서 타깃값을 y변수에 저장해뒀습니다. 사람이 학습할 때 정답이 필요한 것처럼, 머신러닝 모델 훈련 시에도 타깃값(정답)이 필요하기 때문입니다.
다음으로 훈련 데이터에서 일부를 다시 검증 데이터로 나누겠습니다. 훈련 데이터는 모델 훈련에 사용되고, 말 그대로 검증 데이터는 모델 성능 검증에 사용됩니다. 이렇게 나누는 이유는 검증 데이터를 이용해 제출 전에 모델 성능을 평가해보기 위함입니다. 이를 통해 무언가를 수정했을 때 모델 성능이 좋아졌는지 나빠졌는지 판단하는데 도움이 됩니다.
| ※ 앞서 훈련 데이터와 테스트 데이터를 나눌 땐 행 번호로 명확하게 나눌 수 있어서 행을 기준으로 분리했습니다. 하지만 여기서는 훈련 데이터와 검증 데이터를 나눌 때 train_test_split()함수를 사용합니다. 타깃값 공정 배분 여부, 훈련 데이터 / 검증 데이터 비율, 데이터 무작위 추출 등을 설정할 수 있기 때문입니다. |
from sklearn.model_selection import train_test_split
# 훈련 데이터, 검증 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y,
test_size = 0.1,
stratify = y,
random_state = 10)train_test_split()은 전체 데이터를 훈련 데이터와 검증 데이터로 나누는 함수입니다.
첫 번째 인수로는 피처(X_train)를, 두 번째 인수로는 타깃값(y)을 전달합니다.
test_size는 검증 데이터의 크기를 지정하는 파라미터입니다. 이때 값이 정수면 검증 데이터의 개수를, 실수면 비율을 의미합니다. 여기서는 실수인 0.1을 전달했으므로 즉, 10%를 검증 데이터로 분리하겠다는 뜻입니다.
statify는 지정한 값을 각 그룹에 공정하게 배분해주는 파라미터입니다. 즉, 여기서는 타깃값인 y를 전달했으므로 타깃값이 훈련 데이터와 검증 데이터에 같은 비율로 나눠집니다. 만약 stratify 파라미터를 지정하지 않으면 훈련 데이터와 검증 데이터에 타깃값이 불균형하게 분포될 수 있습니다. 그렇게 되면 훈련과 검증이 올바르게 이뤄지지 않으므로 가능한 stratify 파라미터에 타깃값을 넘겨주는게 바람직합니다.
마지막 random_state는 시드값을 고정하여 다음에 실행해도 같은 결과가 나오게 하는 값입니다.
| ※ 검증 데이터가 많을수록 성능 검증 점수를 신뢰할 수 있지만 그만큼 훈련에 사용할 데이터가 적어집니다. 반대로 검증 데이터가 적으면 훈련에 사용할 데이는 많아지지만 성능 검증 점수의 신뢰성이 떨어집니다. 따라 검증 데이터를 적당한 비율로 잡아야 하며, 대체로 10~20% 정도로 합니다. |
이로써 데이터 준비를 마쳤습니다.
베이스라인에서 진행한 피처 엔지니어징 전체 과정은 다음과 같습니다.
1. 훈련 데이터, 테스트 데이터 불러오기
2. 데이터 합치기
3. 원-핫 인코딩
4. 훈련 데이터, 테스트 데이터 나누기
5. 훈련 데이터를 훈련 데이터와 검증 데이터로 나누기
02. 모델 훈련
이제 모델을 생성한 뒤, 앞에서 준비한 데이터를 사용해서 훈련하겠습니다. 선형 회귀 방식을 응용해 분류를 수행하는 로지스틱 회귀 모델을 사용했습니다.
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression(max_iter=1000, random_state=42) # 모델 생성
logistic_model.fit(X_train, y_train) # 모델 훈련간단하게 모델 생성과 훈련이 끝났습니다. 파라미터에 대한 설명은 다음과 같습니다.
● max_iter : 모델의 회귀 개수를 업데이트하는 반복 횟수, 모델 훈련 시 회귀 계수를 업데이트하면서 훈련하는데, 이때 업데이트를 몇 번 할지를 정합니다.
● random_state : 값을 지정하면 여러번 실행해도 매번 똑같은 결과가 나옵니다. 아무 값으로 지정해도 상관 없습니다.
이제 테스트 데이터를 사용해 예측하고 제출하는 일만 남았습니다.
03. 모델 성능 검증
사이킷런은 타깃값 예측 메서드를 두 가지 제공합니다. 바로 predict()와 predict_proba()입니다.
먼저 predict() 메서드는 타깃값 자체(0이냐 1이냐)를 예측합니다.
반면, predict_proba()는 타깃값의 확률(0일 확률과 1일 확률)을 예측한다는 차이점이 있습니다.
다음은 predict_proba()로 검증 데이터와 타깃값이 0 또는 1일 확률을 예측한 결과입니다.
logistic_model.predict_proba(X_valid)
첫 번째 열은 타깃값이 0일 확률을 나타내고, 두 번째 열은 1일 확률을 나타냅니다. 또한 당연히 두 값의 합은 항상 1이 됩니다.
다음은 predict() 메서드로 타깃값을 예측한 결과입니다.
logistic_model.predict(X_valid)
0 또는 1로 예측했습니다. 위의 predict_proba()로 예측한 결과를 비교해봐도 동일하게 첫 번째 열의 확률이 더 높은 경우에는 0으로 두번째 열의 확률 더 높은 경우 1로 예측한 것을 확인할 수 있습니다. 이는 나머지 행도 마찬가지 입니다.
본 대회에서는 타깃값이 1일 '확률'을 예측해야 합니다. 따라서 predict_proba() 메서드로 예측한 결과의 두 번째 열을 타깃 예측값으로 사용합니다.
검증 데이터를 활용한 타깃을 예측해보겠습니다.
# 검증 데이터를 활용한 타깃 예측
y_valid_preds = logistic_model.predict_proba(X_valid)[:, 1]y_valid_preds 변수에 검증 데이터 타깃값이 1일 확률이 저장됩니다.
이제 타깃 예측값인 y_valid_preds와 실제 타깃값인 y_valid를 이용해 ROC AUC를 구해보겠습니다. 이는 모델 성능을 검증하려는 절차에 해당합니다. ROC AUC 점수는 사이킷런의 roc_aud_score()함수를 이용하면 구할 수 있습니다.
from sklearn.metrics import roc_auc_score # ROC AUC 점수 계산 함수
# 검증 데이터 ROC AUC
roc_auc = roc_auc_score(y_valid, y_valid_preds)
print(f'검증 데이터 ROC AUC : {roc_auc:.4f}')
04. 예측 및 결과 제출
이제 '테스트 데이터'를 활용해 타깃값이 1일 확률을 예측하고 결과를 제출해보겠습니다.
# 타깃값 1일 확률 예측
y_preds = logistic_model.predict_proba(X_test)[:, 1y_preds에 타깃값 1일 확률을 저장했습니다.
마지막으로 제출 파일을 만듭니다.
# 제출 파일 생성
submission['target'] = y_preds
submission.to_csv('submission.csv')끝났습니다. 커밋후 제출해 보겠습니다.
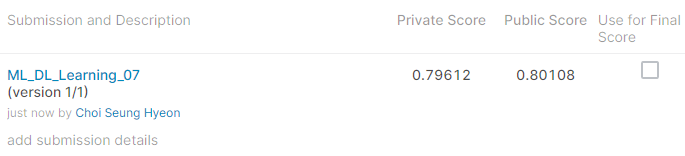
프라이빗 점수는 0.79612, 퍼블릭 점수는 0.80108이 나왔습니다. 프라이빗 점수는 대회가 종료된 후 전체 테스트 데이터로 평가한 점수 입니다. 반면에 퍼블릭 점수는 대회가 종료되기 전, 테스트 데이터 일부만 사용해 평가한 점수입니다. 따라서 프라이빗 점수가 최종 점수이며, 퍼블릭 점수는 큰 의미가 없습니다.
이제 모델을 개선해서 점수를 더 높여보도록 하겠습니다.
2. 성능 개선Ⅰ
베이스 라인 모델 자체의 성능을 높여보겠습니다.
전체적인 순서는 아래의 표와 같습니다.
| 데이터 불러오기 | |
| 피처 엔지니어링 | 1. 피처 맞춤 인코딩 2. 피처 스케일링 |
| 평가지표 계산 함수 작성 | ROC AUC (사이킷런 제공) |
| 하이퍼파라미터 최적화 (모델 훈련) | 모델 : 로지스틱 회귀 최적화 : 그리드 서치 |
| 성능 검증 | |
| 제출 | |
성능 향상을 위해 다음 세 가지에 주의하며 모델링을 진행하겠습니다.
1. 피처 맞춤 인코딩
2. 피처 스케일링
3. 파이퍼파리미터 최적화
첫 번째, 인코딩을 피처 특성에 맞게 적용합니다. 이진 피처와 순서형 피처 ord_01, ord_02 는 수작업으로 인코딩을 해줄 겁니다. 그리고 순서형 피처 ord_3, ord_4, ord_5는 ordinal 인코딩을, 명목형 피처와 날짜 피처에는 원-핫 인코딩을 적용합니다.
두 번째, 피처 스케일링을 적용합니다. 피처 스케일링은 피처 간 값의 범위를 일치시키는 작업입니다. 피처마다 값의 범위가 다르다면 훈련이 제대로 안 될 수 있습니다. 피처 스케일링을 순서형 피처에만 적용합니다. 왜냐하면 이진 피처를 값이 두 개라서 인코딩을 해도 0과 1로만 구성되고, 명목형 피처와 날짜 피처도 원-핫 인코딩 후 0과 1로 구성될 것이기 때문입니다. 다시 말해, 이진 피처, 명목형 피처, 날짜 피처는 인코딩 이후 이미 최솟값 0, 최댓값 1로 범위가 일치하기에 스케일링이 필요가 없습니다.
세 번째, 하이퍼파라미터를 최적화합니다. 최적 하이퍼파라미터로 모델을 훈련하고 제출해 점수를 올려보겠습니다.
우선 데이터를 불러옵니다.
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/cat-in-the-dat/'
train = pd.read_csv(data_path + 'train.csv', index_col='id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')01. 피처 엔지니어링 Ⅰ : 피처 맞춤 인코딩
베이스라인에서는 모든 피처를 일괄적으로 원-핫 인코딩했습니다. 그러나 피처 특성에 맞게 인코딩한다면 성능이 더 좋아질 수 있습니다.
이번에 진행할 인코딩 절차를 정리하면 아래와 같습니다.
| 원본 데이터 (all_data) |
| 1. 이진 피처 인코딩 (수작업) |
| 2. 순서형 피처 인코딩 (수작업, OrdianalEncoder) |
| 3. 명목형, 날짜 피처 인코딩 (원-핫 인코딩) |
| 4. 모든 작업이 끝난 후 합치기 |
- 데이터 합치기
인코딩 전에 훈련 데이터와 테스트 데이터를 합쳐 all_data를 만들고 타깃값은 제거합니다.
# 훈련 데이터와 테스트 데이터 합치기
all_data = pd.concat([train, test])
all_data = all_data.drop('target',axis=1) # 타깃값 제거- 이진 피처 인코딩
첫 번째로 이진 피처를 인코딩 하겠습니다.

이전에 봤던 '이진 피처 요약표'입니다. 보이듯이 bin_0, bin_1, bin_2 피처는 이미 0과 1로 이루어져 있기에 따로 인코딩하지 않아도 됩니다.
하지만 bin_3, bin_4 피처는 각각 T와 F, Y와 N이라는 문자로 구성돼 있습니다. 각가 1과 0으로 바꾸겠습니다. 이때 판다스의 map() 함수를 사용합니다.
all_data['bin_3'] = all_data['bin_3'].map({'F':0,'T':1})
all_data['bin_4'] = all_data['bin_4'].map({'N':0,'Y':1})DataFrame의 열(피처)을 호출하면 반환값이 Series 타입입니다. Series 객체에 map() 함수를 호출하면, 전달받은 딕셔너리나 함수를 Series의 모든 원소에 적용해 결과를 반환합니다. 여기서는 map() 함수에 딕셔너리를 전달했습니다.
딕셔너리를 이용해 bin_3의 F와 T는 각각 0과 1로, bin_4의 N와 Y 역시 각각 0과 1로 바꿨습니다. 이상으로 이진 피처들은 수작업으로 간단하게 인코딩을 완료했습니다.
- 순서형 피처 인코딩
다음으로 순서형 피처를 인코딩 하겠습니다. 순서형 피처의 고윳값은 다음과 같습니다.

ord_0 피처는 이미 숫자로 구성돼 있어 인코딩 하지 않아도 됩니다. ord_1과 ord_2 피처는 순서를 정해서 인코딩해보겠습니다. ord_3부터 ord_5는 알파벳 순서대로 인코딩해야 합니다.
ord_1과 ord_2 피처부터 인코딩 해보겠습니다. 이번에도 map() 함수를 사용해 수작업으로 인코딩합니다. 이때 피처 값 순서에 유의해야 합니다.
ord1dict = {'Novice':0, 'Contributor':1, 'Expert':2, 'Master':3, 'Grandmaster':4}
ord2dict = {'Freezing':0, 'Cold':1, 'Warm':2, 'Hot':3, 'Boiling Hot':4, 'Lava Hot':5}
all_data['ord_1'] = all_data['ord_1'].map(ord1dict)
all_data['ord_2'] = all_data['ord_2'].map(ord2dict)ord_1, ord_2 피처 인코딩이 끝났습니다.
다음은 ord_3, ord_4, ord_5 차례입니다. 이 피처들은 알파벳 순서대로 인코딩해야 합니다.. 사이킷런의 OridianlEncoder를 사용하면 됩니다.
| ※ map() 로 인코딩 해도 되지만, 고유값의 개수가 많아 번거롭기 때문에 OridinalEncoder를 사용합니다. |
우선 OrdinalEncoder 객체를 생성하고, ord_3, ord_4, ord_5 피처에 fit_transform()을 적용해 인코딩합니다. 알파벳순으로 잘 인코딩됐는지도 출력해보겠습니다.
from sklearn.preprocessing import OrdinalEncoder
ord_345 = ['ord_3','ord_4','ord_5']
ord_encoder = OrdinalEncoder() # OrdinalEncoder 객체 생성
# ordinal 인코딩 적용
all_data[ord_345] = ord_encoder.fit_transform(all_data[ord_345])
# 피처별 인코딩 순서 출력
for feature, categories in zip(ord_345, ord_encoder.categories_):
print(feature)
print(categories)
ord_encoder.categories_는 어떤 순서로 ordianl 인코딩을 적용했는지 보여줍니다. 출력 결과를 보니 알파벳순으로 제대로 인코딩 된것을 알 수 있습니다. 알파벳 순서에 따라 0부터 차례대로 인코딩 됩니다.
- 명목형 피처 인코딩
명목형 피처는 순서를 무시해도 되기 때문에 원-핫 인코딩을 적용합니다. 먼저 지능형 리스트를 활용해 명목현 피처 리스트를 만듭니다. 명목형 미처는 nom_0 부터 nom_9까지 총 10개 입니다.
참고로 지능형 리스트는 코드 한 줄로 새로운 리스트를 만드는 문법 구조를 의미합니다.
nom_features = ['nom_'+str(i)for i in range(10)] # 명목형 피처이 명목형 피처를 원-핫 인코딩해 별도 행렬에 저장하고, 이어서 all_data에서 명목형 피처를 삭제하겠습니다. 원-핫 인코딩을 하면 열 개수가 늘어나서 all_data에서 곧바로 인코딩할 수 때문입니다. 따라 다음과 같은 코드는 실행이 되지 않습니다.
'''# 정상 실행되지 않는 코드(오류 발생)
from sklearn.preprocessing import OneHotEncoder
onehot_encoder = OneHotEncoder()
all_data[nom_features] = onehot_encoder.fit_transform(all_data[nom_features])'''정상적으로 실행되는 코드는 다음과 같습니다.
# 정상 실행되는 코드
from sklearn.preprocessing import OneHotEncoder
onehot_encoder = OneHotEncoder() # OneHotEncoder 객체 생성
# 원-핫 인코딩 적용
encoded_nom_matrix = onehot_encoder.fit_transform(all_data[nom_features])
encoded_nom_matrix
OneHotEncoder로 원-핫 인코딩을 적용하면 희소 행렬을 CSR 형식으로 반환합니다. 출력 결과를 보면 원-핫 인코딩된 명목형 피처의 행렬 크기가 ( 500000 x 16276) 입니다. 원-핫 인코딩 때문에 열이 16,276개나 생성된 것입니다.
명목형 피처를 원-핫 인코딩한 결과를 encoded_nom_matrix에 저장했습니다. 이는 CSR 형식의 행렬입니다.
마지막으로 all_data에서 기존 명목형 피처를 삭제하겠습니다. 추후 encoded_nom_matrix 와 all_data를 합칠 텐데, 그러면 하나의 피처가 형식만 다르게 중복되어 들어가기 때문입니다.
all_data = all_data.drop(nom_features, axis=1) # 기존 명목형 피처 삭제- 날짜 피처 인코딩
day와 month는 날짜 피처입니다. 날짜 피처 역시 원-핫 인코딩을 적용하겠습니다.
date_features = ['day', 'month'] # 날짜 피처
# 원-핫 인코딩 적용
encoded_date_matrix = onehot_encoder.fit_transform(all_data[date_features])
all_data = all_data.drop(date_features, axis=1) # 기존 날짜 피처 삭제
encoded_date_matrix
원-핫 인코딩된 행렬 크기는 (500000 x 19) 입니다. 이는 day 피처 고윳값은 7개, month 피처 고윳값은 12개라서 인코딩 후 열이 총 19개가 되었습니다.
02. 피처 엔지니어링 Ⅱ : 피처 스케일링
피처 스케일링이란 서로 다른 피처들의 값의 범위가 일치하도록 조정하는 작업입니다. 피처 스케일링이 필요한 이유는 수치형 피처들의 유효 값 범위가 서로 다르면 훈련이 제대로 안 될 수도 있기 때문입니다.
앞에서는 이진, 명목형, 날짜 피처를 모두 0과 1로 인코딩 했습니다. 하지만 순서형 피처는 여전히 여러 가지 값을 갖고 있으므로 순서형 피처의 값 범위도 0~1 사이가 되도록 스케일링해주겠습니다.
- 순서형 피처 스케일링
다른 피처들과 범위를 맞추기 위해 순서형 피처에 min-max 정규화를 적용하겠습니다. min-max 정규화는 피처의 값의 범위를 0에서 1로 조정합니다.
from sklearn.preprocessing import MinMaxScaler
ord_features = ['ord_' + str(i) for i in range(6)]
# min-max 정규화
all_data[ord_features] = MinMaxScaler().fit_transform(all_data[ord_features])이로 모든 피처 값의 범위가 0~1로 맞춰졌습니다.
이상으로 모든 피처가 적절히 인코딩됐고, 피처 값들의 범위도 같아졌습니다.
- 인코딩 및 스케일링된 피처 합치기
현재 all_data에는 이진 피처와 순서형 피처가 인코딩돼 있습니다. 명목형 피처와 날짜 피처는 원-핫 인코딩되어 각각 encoded_nom_matrix와 encoded_date_matrix에 저장돼 있습니다. 이 세 데이터를 합치겠습니다.
그런데 all_data는 DataFrame 이고, encoded_nom_matrix와 encoded_date_matrix는 CSR 형식의 행렬입니다. 형식이 서로 다르니 맞춰주는 작업이 필요합니다. 따라 all_data를 CSR 형식으로 만들어 합치겠습니다. 사이파이가 제공하는 csr_matrix()는 전달받은 데이터를 CSR 형식으로 바꿔줍니다.
from scipy import sparse
#인코딩 및 스케일링된 피처 합치기
all_data_sprs = sparse.hstack([sparse.csr_matrix(all_data),
encoded_nom_matrix,
encoded_date_matrix],
format='csr')여기서 hstack()은 행렬을 수평 방향으로 역할을 합니다. 그리고 format='csr'을 전달하면 합친 결과를 CSR 형식으로 반환 합니다(기본값은 COO 형식입니다). 인코딩된 모든 피처를 합친 all_data_sprs를 출력하면 다음과 같습니다.

500,000행 16,306열로 구성돼 있습니다 이 정도 크기를 DataFrame으로 처리하면 메모리 낭비가 심하고 훈련 속도도 떨어집니다. 따라서 DataFrame으로 변환하지 않고, CSR 형식을 그대로 사용하겠습니다.
이상으로 피처 엔지니어링을 모두 마쳤습니다.
- 데이터 나누기
마지막으로 훈련 데이터와 테스트 데이터로 나눕니다.
num_train = len(train) # 훈련 데이터 개수
# 훈련 데이터와 테스트 데이터 나누기
X_train = all_data_sprs[:num_train] # 0~num_train - 1행
X_test = all_data_sprs[num_train:] # num_train~마지막 행
y = train['target']y는 모델 훈련 시 필요한 타깃값(정답)입니다.
from sklearn.model_selection import train_test_split
# 훈련 데이터, 검증 데이터 분리
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y,
test_size=0.1,
stratify=y,
random_state=10)베이스라인과 마찬가지로 훈련 데이터를 다시 훈련 데이터와 검증 데이터로 나눠주겠습니다.
03. 하이퍼파리미터 최적화
최종 데이터를 활용해 모델을 훈련하고 결과를 제출하겠습니다. 이 과정에서 베이스라인 모델과 달리 하이퍼파라미터를 최적화해보겠습니다.
그리드서치를 활용해 로지스틱 회귀 모델의 하이퍼파라미터를 최적화해보겠습니다. 탐색할 하이퍼파라미터는 C와 max_iter 입니다. C는 규제 강도를 조절하는 파라미터로, 값이 작을수록 규제 강도가 세집니다.
모델을 생성하고 평가지표를 ROC AUC로 지정해 그리드서치를 수행해보겠습니다.
참고로 다음 코드는 실행하는데 수 분이 걸립니다. 또한 첫 줄의 %%time은 해당 셀 실행 후 소요 시간을 출력해 주는 기능입니다.

저는 약 6분이 걸렸습니다. CPU 시간의 총합이 Wall time보다 큰 이유는 이 코드를 병렬로 실행했기 때문입니다. CPU 시간은 개별 코어의 수행 시간을 모두 합친 값입니다.
최적 하이퍼파라미터는 C는 0.125 일 때, max_iter 는 800 인 경우 입니다.
04. 모델 성능 검증
최적 하이퍼파라미터를 찾았으니 모델 성능이 얼마나 개선되는지 확인해 보겠습니다. 베이스라인처럼 검증 데이터로 모델 성능을 검증해보겠습니다. 먼저 검증 데이터로 타깃 예측값을 구합니다.
y_valid_preds = gridsearch_logistic_model.predict_proba(X_valid)[:, 1]이어서 검증 데이터 ROC AUC도 구하겠습니다.

ROC AUC가 0.8045 입니다. 베이스라인 모델모다 0.008 만큼 향상되었습니다.
05. 예측 및 결과 제출
제출 파일을 만들어 커밋 후 제출해보겠습니다.
# 타깃값 1일 확률 예측
y_preds = gridsearch_logistic_model.best_estimator_.predict_proba(X_test)[:,1]
# 제출 파일 생성
submission['target'] = y_preds
submission.to_csv('submission.csv')
베이스 라인 모델보다 프라이빗 점수는 0.00608, 퍼블릭 점수는 0.00698 만큼 점수가 높습니다. 하지만 여기서 성능을 더 높이는 방법 역시 존재합니다.
2. 성능 개선 Ⅱ
간단한 방법으로 위에서 바로 제출한 점수를 더 높일 수 있습니다.
앞서 모델 훈련 시 전체 훈련 데이터를 9:1 비율로 훈련 데이터와 검증 데이터로 나눴습니다.
훈련 데이터는 훈련용으로만 사용하고, 검증 데이터는 모델 성능 검증용으로만 사용했습니다.
검증 데이터는 전체 훈련 데이터의 10%를 차지합니다. 이렇게 많은 데이터를 검증용으로만 사용하는 것은 아깝습니다. 따라 지금까지의 모델링 절차를 그대로 유지한 채로 훈련 데이터 전체를 사용해 모델을 훈련해보겠습니다.
즉, train_test_split()으로 훈련 데이터 (90%)와 검증 데이터(10%)로 나누는 부분과 연관된 코드를 제외하고 모든 절차는 앞의 '성능 개선 Ⅰ'과 동일합니다.
동일한 과정 이후, 아래의 부분만 유의하면 됩니다

커밋 후 제출의 결과는 아래와 같습니다.
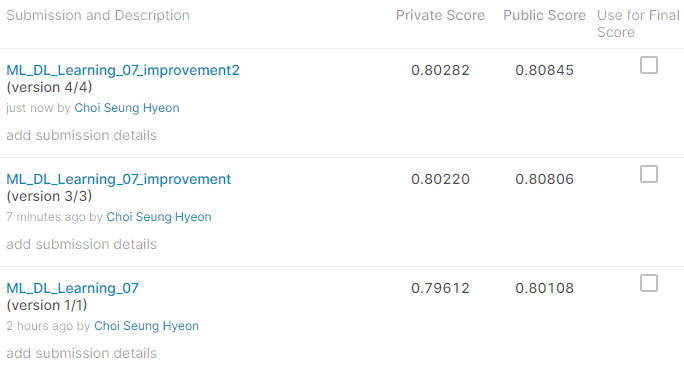
프라이빗 점수가 0.80282 입니다. 앞의 90% 훈련 데이터만으로 모델링했을 때는 프라이빗 점수가 0.80220 이었으니 0.0062만큼 향상된 것을 확인할 수 있습니다.
마지막에서 가장 중요한 것은 가장 성능이 좋은 모델을 다시 한 번 전체 훈련 데이터로 학습을 시켜서 확인해야 한다는 점입니다!